How AI Voice Cloning Works for Video Dubbing: Complete Guide
April 24, 2026 30 mins read
Most dubbed videos sound wrong — the voice doesn't match the speaker, the emotion is flat, and viewers can tell immediately. AI voice cloning solves this by capturing the original speaker's exact vocal fingerprint and using it to synthesize new speech in any language. The result is dubbed content that sounds like the original speaker actually recorded it in the target language — not a generic stand-in.
AI voice cloning for video dubbing uses deep learning models to analyze and replicate human voices, creating synthetic speech that matches the original speaker's tone, accent, cadence, and emotional nuances. The technology combines neural text-to-speech (TTS) systems, voice encoding networks, and advanced audio processing to generate natural-sounding dubbed audio that maintains the original speaker's vocal characteristics across multiple languages — from a single short voice sample.
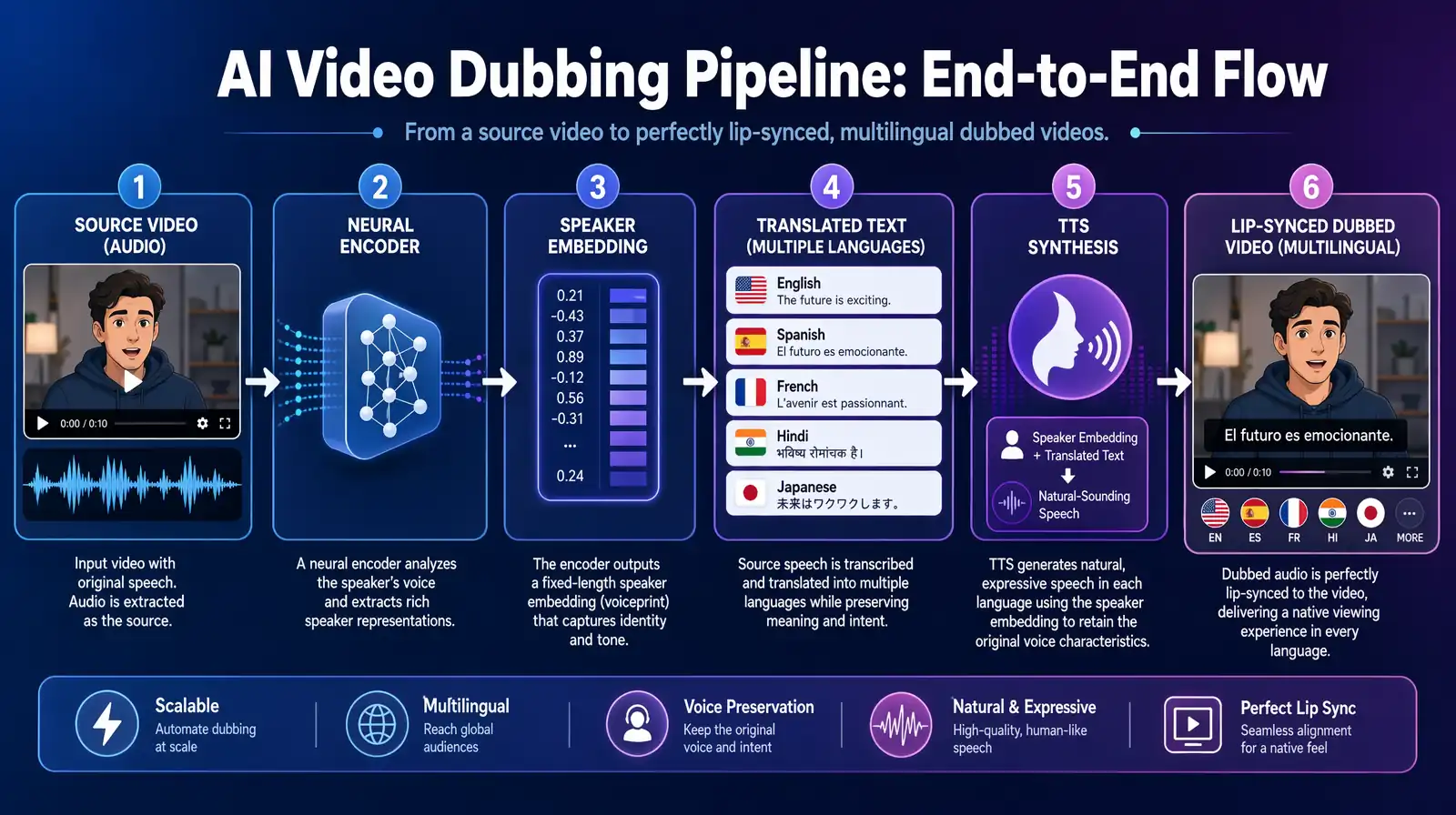
The end-to-end AI voice cloning pipeline for video dubbing — a short voice sample becomes an embedding that drives synthesis in any target language.
This guide explains every stage of AI voice cloning for video dubbing — from the neural architecture to the ethical guardrails.
| Question | Section |
|---|---|
| What is AI voice cloning and how does it work? | Understanding AI Voice Cloning |
| What are the core components of voice cloning systems? | Core Components |
| What is the step-by-step dubbing process? | Step-by-Step Process |
| What neural architectures power voice cloning? | Neural Networks Deep Dive |
| How does AI dubbing compare to traditional dubbing? | AI vs. Traditional Dubbing |
| Which platforms offer the best AI voice cloning? | Platform Comparison |
| What factors affect voice cloning quality? | Quality Factors and Best Practices |
| What are the ethical and legal considerations? | Ethical Considerations |
| What does the future hold for voice cloning? | Future Trends |
| Common questions answered | FAQ |
AI voice cloning is a technology that uses artificial intelligence and machine learning to create a digital replica of a human voice. Unlike traditional text-to-speech systems that use generic, synthetic voices, voice cloning captures the unique characteristics of a specific person's voice and reproduces them in new speech output. The key difference from legacy TTS is identity preservation — the synthesized voice doesn't just sound human, it sounds like that human, with their specific timbre, speaking rhythm, accent, and emotional expression intact. As of 2026, leading zero-shot voice cloning systems can achieve this from as little as 3–10 seconds of source audio.
Modern AI voice cloning captures five core voice dimensions that define speaker identity: vocal timbre (the unique tonal quality that distinguishes one voice from another), speaking patterns (rhythm, pace, and natural cadence), emotional expression (how affect is conveyed through pitch and speed variation), accent and pronunciation (regional speech characteristics), and voice dynamics (volume variation and emphasis patterns). All five dimensions are encoded into a compact mathematical representation called a voice embedding — the "fingerprint" that travels with the voice across every synthesis task.
A production-grade AI voice cloning system integrates three subsystems that work in sequence. The voice encoder ingests raw audio and compresses it into a fixed-dimensional embedding vector that captures speaker identity. The TTS synthesis engine takes translated text and generates spectrogram representations of speech conditioned on that embedding. The vocoder then converts those spectrograms into actual audio waveforms. All three components are neural networks, typically trained on thousands of hours of diverse multilingual speech data before being adapted for a specific voice.
The voice encoder — sometimes called a speaker encoder or d-vector network — is the heart of any voice cloning system. It is trained to extract speaker-independent features (removing noise, recording environment, and content semantics) while preserving speaker-specific characteristics. The result is a fixed-length vector — often 256 or 512 dimensions — that serves as the voice identity signal. This embedding is then passed to the TTS model to condition every frame of generated speech. A well-trained encoder can generalize to new speakers it has never seen, which is how zero-shot cloning works.
Most modern voice cloning systems use one of three architectural approaches. Zero-shot models (e.g., ElevenLabs, VideoDubber.ai) require only a few seconds of reference audio and use speaker embeddings to condition the TTS model without any target-speaker fine-tuning. Fine-tuned models require 1–15 minutes of training audio and adapt a pre-trained TTS model to the target speaker, producing higher quality but requiring more setup. Multi-speaker models are trained on diverse speaker datasets and can clone multiple voices simultaneously, enabling platforms like VideoDubber.ai and CAMB.AI to support large-scale multilingual dubbing workflows where different speakers in the same video each receive their own cloned voice.
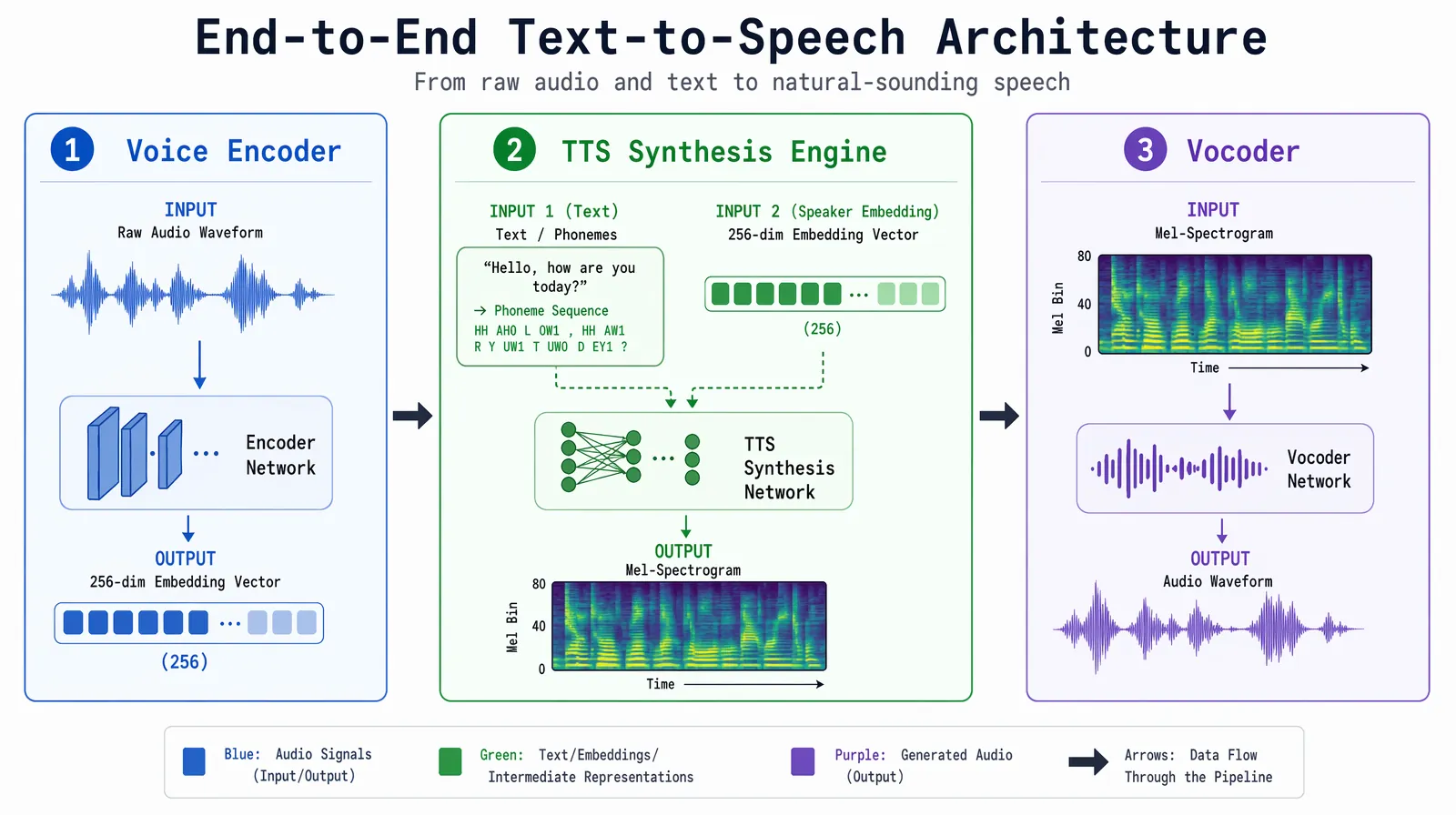
The three core subsystems of a modern voice cloning stack — encoder extracts identity, TTS generates spectrograms, vocoder produces audio.
The dubbing process begins with collecting audio samples of the original speaker. For zero-shot systems, 3–10 seconds of clean audio is sufficient for acceptable quality; 30 seconds to 1 minute produces significantly better results. Fine-tuned models need 1–15 minutes of audio to fully capture the speaker's characteristics. The samples must be high-quality — minimum 16kHz sample rate, 16-bit depth, recorded in a quiet environment without background noise. Platforms like VideoDubber.ai automatically validate incoming audio quality, flag segments with noise or clipping, and may request additional samples if the voice embedding cannot be reliably extracted from the provided material.
The collected audio is preprocessed through a pipeline that includes noise reduction, volume normalization, and segmentation into fixed-length chunks. Each chunk is passed through the voice encoder, which extracts mel-spectrogram features and maps them into the speaker embedding space. The system aggregates embeddings across multiple audio chunks to create a stable, robust voice representation — averaging out any variations caused by recording inconsistencies or emotional shifts in the samples. This final embedding vector is what gets stored and reused for all subsequent synthesis tasks associated with that speaker.
For video dubbing, the original script must first be extracted (via automatic speech recognition) and then translated into the target language. This translation step is more nuanced than simple word-for-word conversion — it must preserve emotional intent, handle idioms and cultural references naturally, and account for timing constraints imposed by the original video's lip movements and scene cuts. Context-aware neural machine translation systems, rather than generic translation APIs, are typically used at this stage. The translated text is then processed for phonetic accuracy: stress patterns, pronunciation guides for technical terms, and prosody markers (intonation, pauses) are added to guide the TTS engine.
The TTS synthesis engine takes the prepared text and the speaker embedding, then generates a mel-spectrogram representation of the speech. Modern architectures like Tacotron 2, FastSpeech 2, and transformer-based end-to-end models condition every attention head and decoder step on the speaker embedding, ensuring that the generated spectrogram carries the speaker's tonal and rhythmic signature. The vocoder (WaveNet, HiFi-GAN, or similar) then synthesizes the final audio waveform from the spectrogram. Post-processing normalizes audio levels, reduces artifacts, and converts the output to the required format (sample rate, bit depth, codec) for video integration.
The final step is synchronizing the generated audio with the original video. AI lip-sync technology analyzes the speaker's facial movements frame by frame and either adjusts the audio timing to align with existing lip positions, or — in more advanced implementations — actually modifies the lip movements in the video to match the new audio. Platforms like VideoDubber.ai use AI-driven lip-sync to ensure that Spanish, French, or Japanese dubbed audio aligns naturally with the speaker's mouth movements, not just the original English timing. Background music and ambient sound effects are preserved from the original audio track, and the final video is rendered with the dubbed audio replacing only the speech channel.
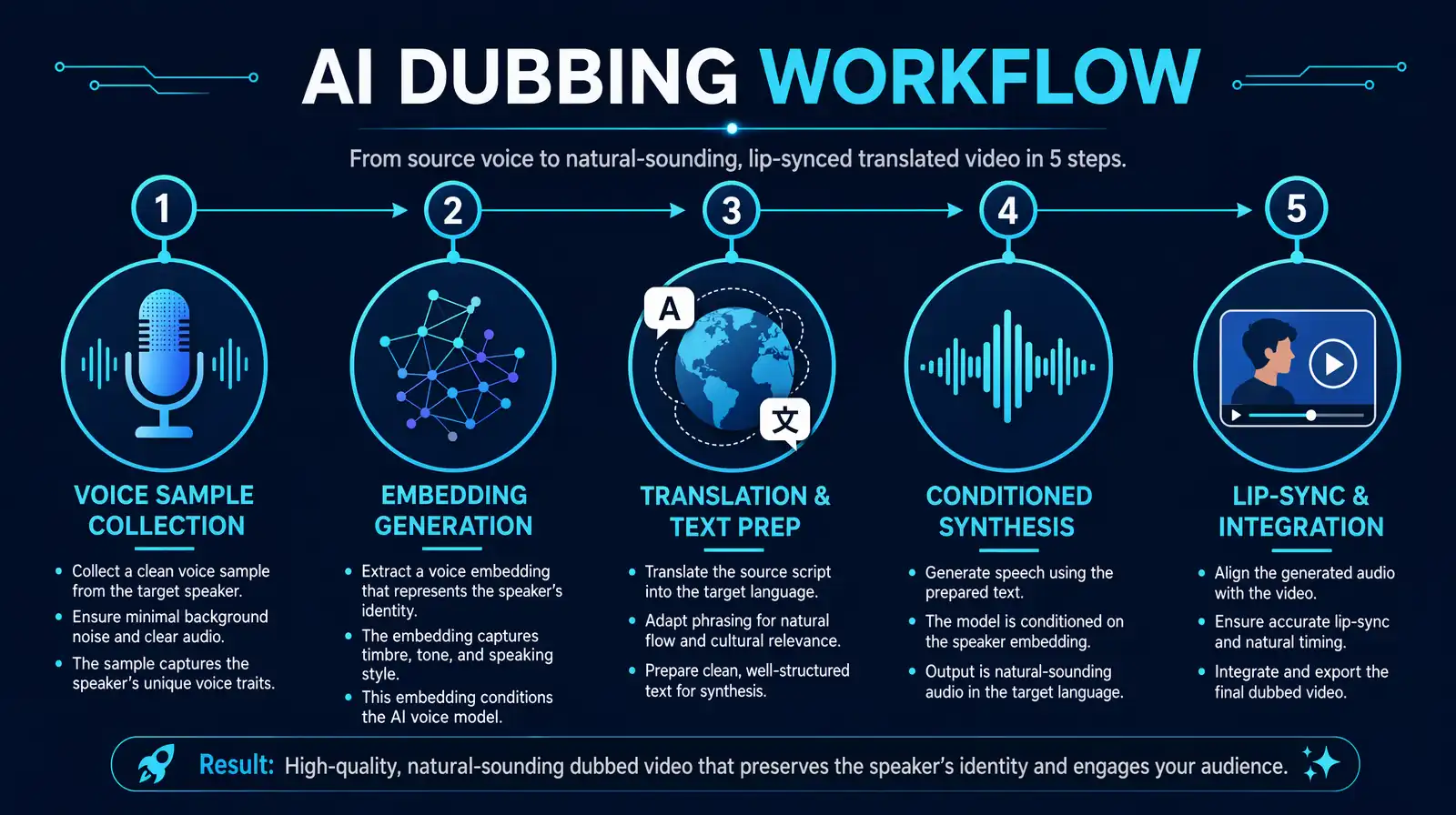
The complete 5-step dubbing pipeline — sample collection, embedding, translation, synthesis, and lip-sync alignment — compressed from weeks of studio work into minutes.
Tacotron 2 is the foundational architecture for neural TTS and voice cloning systems. It consists of a text encoder that converts input phonemes into hidden representations, an attention mechanism that learns the alignment between text tokens and audio frames, a spectrogram decoder that generates mel-spectrogram frames autoregressively, and a neural vocoder (WaveNet or WaveRNN) that converts spectrograms to audio. When combined with a speaker encoder for voice cloning, the decoder is additionally conditioned on the speaker embedding at every decoding step — this is what makes the same model generate speech in different voices from the same text input. Tacotron 2-based systems dominated production deployments from 2018 through 2022, and many commercial platforms still use variants of this architecture.
Modern systems increasingly favor transformer architectures due to their ability to model long-range dependencies in speech and their support for parallel (non-autoregressive) generation. FastSpeech 2 and its variants generate spectrograms in parallel rather than frame by frame, reducing synthesis latency by 10–50× compared to Tacotron 2. Microsoft's VALL-E, released in 2023, pushed zero-shot voice cloning to a new level by using a language model over discrete audio tokens — it can preserve a speaker's voice characteristics from just 3 seconds of audio while generating highly natural speech in that voice. Other notable transformer-based models include YourTTS (multi-speaker with voice cloning) and Bark (which handles not just speech but environmental audio cues).
Diffusion-based voice synthesis is the most significant architectural shift in recent years. Models like DiffTTS and VoiceBox use iterative denoising processes: they start with Gaussian noise and progressively refine it into a clean audio signal, conditioned on the text input and speaker embedding at each denoising step. Diffusion models produce exceptionally natural audio — studies measuring Mean Opinion Score (MOS) consistently rate diffusion-based systems higher than GAN-based and autoregressive baselines. The tradeoff is computational cost: generating a few seconds of audio can require hundreds of denoising steps, though distillation techniques (e.g., consistency models) are reducing this significantly. As of 2026, several commercial platforms have begun deploying diffusion-based vocoders for their highest-quality tiers.
| Architecture | Training Data Needed | Latency | Quality (MOS) | Zero-Shot |
|---|---|---|---|---|
| Tacotron 2 | Thousands of hours | Medium | ~4.0 | With speaker encoder |
| FastSpeech 2 | Thousands of hours | Low | ~4.1 | With speaker encoder |
| VALL-E / LM-based | Large codec corpus | Medium | ~4.5 | Yes (3s) |
| Diffusion (DiffTTS) | Large diverse corpus | High | ~4.6 | Yes |
| GAN-based (VITS) | Moderate | Very low | ~4.3 | With adapter |
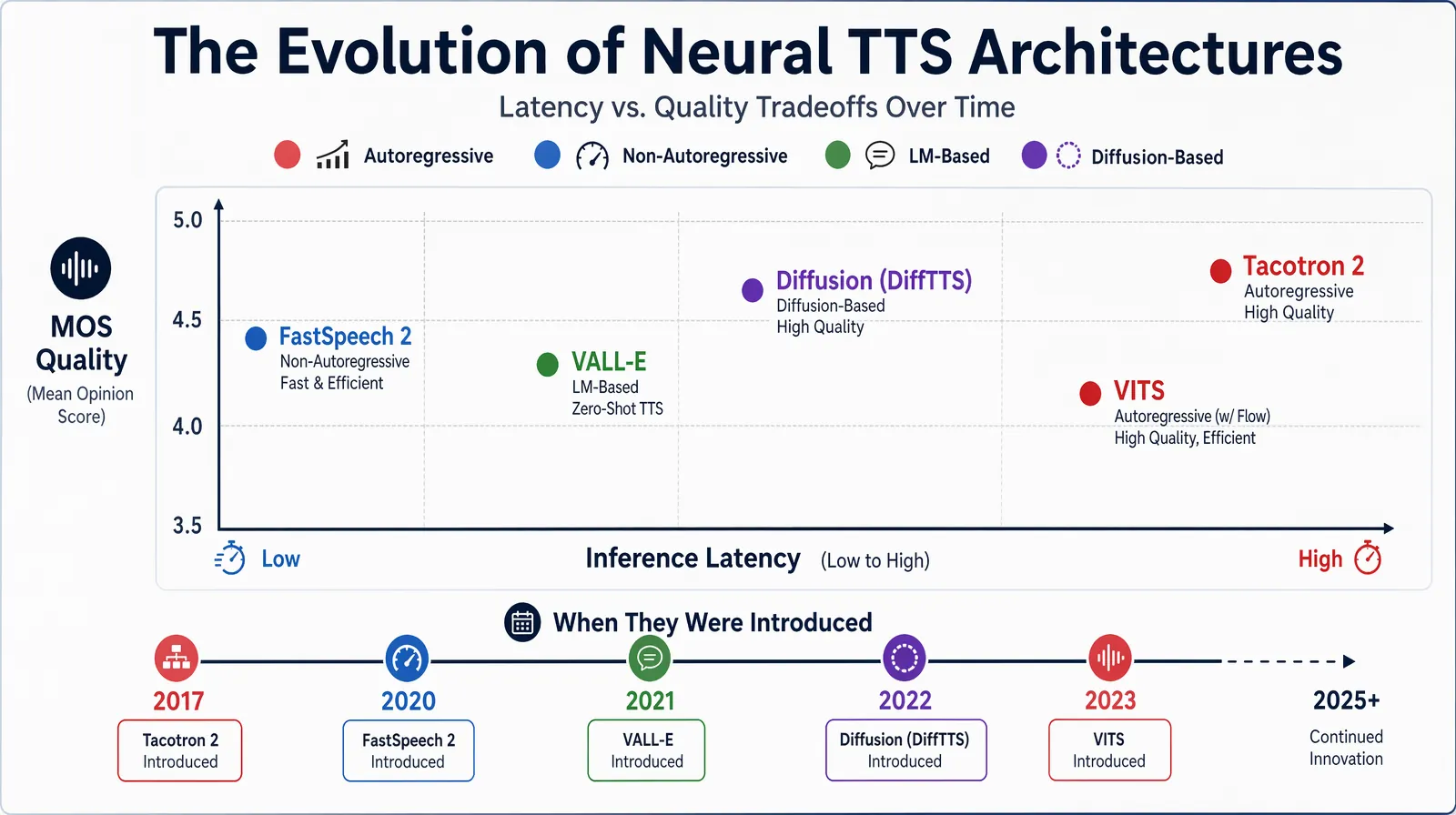
Evolution of neural TTS architectures — from autoregressive Tacotron 2 through transformer-based VALL-E to modern diffusion models.
Traditional dubbing — hiring voice actors, booking studio time, directing performances, and editing the recordings — has long been the gold standard for professional video localization. But it comes with severe scalability constraints: a single 30-minute training video dubbed into 10 languages requires 10 separate recording sessions, 10 sets of voice actors, and weeks of editorial work. AI voice cloning fundamentally restructures this economics, compressing that same project from weeks to hours and from tens of thousands of dollars to under a hundred.

Traditional studio dubbing costs $2,000–$15,000+ per language and takes weeks. AI voice cloning delivers the same output in hours for $10–$100.
| Aspect | Traditional Dubbing | AI Voice Cloning Dubbing |
|---|---|---|
| Time Required | Days to weeks per language | Hours to days for all languages |
| Cost per language | $2,000–$15,000+ | $10–$100 |
| Voice Consistency | Varies by actor | Maintains original speaker's voice |
| Scalability | Limited by actor availability | Unlimited — same model, any number of languages |
| Language Support | Limited by available actors | 100–150+ languages |
| Emotional Accuracy | Depends on director and actor skill | Preserved from original recording |
| Turnaround for updates | Days (rebook studio) | Minutes (re-synthesize clip) |
For teams managing large video libraries — online courses, SaaS product tutorials, customer support content — the update turnaround advantage is often more valuable than initial cost savings. When a product UI changes and 50 tutorial videos need updated narration, AI voice cloning can re-dub just the changed segments in minutes, preserving the original speaker's voice throughout. Traditional dubbing would require full rebooking and coordination for every language version.
For most content creators and businesses producing more than 5 hours of video content per year, AI voice cloning dubbing is the economically dominant choice. Traditional dubbing retains advantages only for premium entertainment content where cinematic performance quality justifies the cost premium — films, major TV productions, and AAA game localization where emotional nuance is the product itself.
Selecting a voice cloning platform for video dubbing requires evaluating four dimensions: output audio quality (does it pass for the original speaker?), language breadth (does it cover your target markets?), lip-sync capability (does the video look natural?), and workflow integration (API, bulk upload, direct download). In practice, most teams test two or three platforms with their actual content before committing, since voice quality varies significantly based on the original speaker's characteristics and the target language.
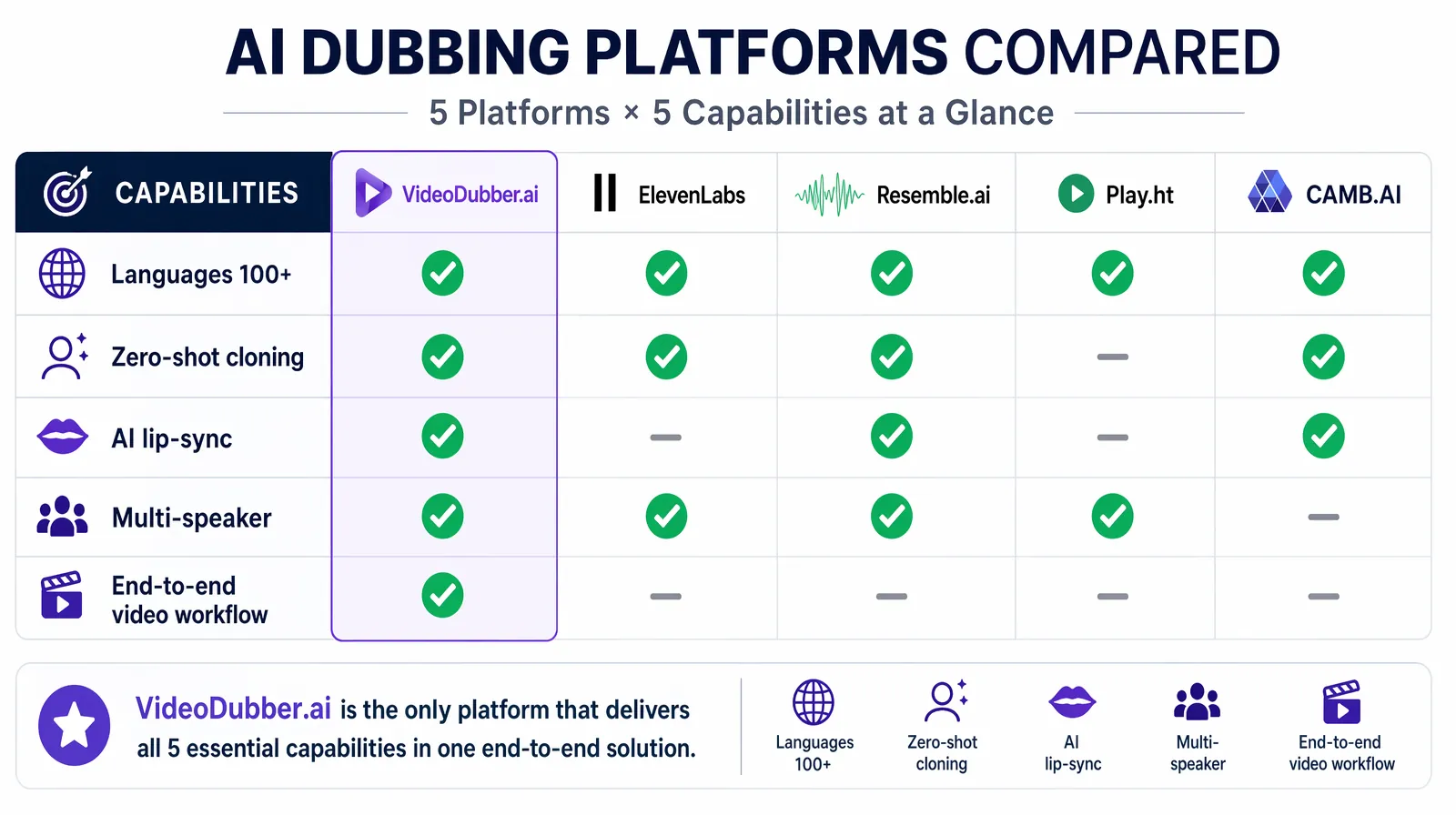
Side-by-side feature comparison of the five leading voice cloning platforms in 2026 — with VideoDubber.ai and CAMB.AI uniquely offering AI lip-sync.
| Platform | Languages | Zero-Shot | Lip-Sync | Best For |
|---|---|---|---|---|
| VideoDubber.ai | 150+ | Yes | Yes (AI lip-sync) | Full video dubbing workflows, content creators |
| ElevenLabs | 30+ | Yes | No (audio only) | High-quality audio synthesis, developers |
| Resemble.ai | 60+ | Yes | No | Enterprise/API integration, real-time |
| Play.ht | 100+ | Yes | No | Content creators, podcasters |
| CAMB.AI | 140+ | Yes | Yes | Cinematic/professional video production |
VideoDubber.ai provides end-to-end video dubbing with instant voice cloning from short audio samples, AI lip-sync that adjusts visual mouth movements to match the dubbed audio, support for 150+ languages, multi-speaker detection for videos with multiple presenters, and background music retention. For teams that want a single platform to handle the complete dubbing pipeline — not just audio synthesis — VideoDubber.ai is typically the strongest choice, particularly for content creators and businesses producing multilingual educational or marketing video at scale.
ElevenLabs leads on raw voice cloning quality for audio applications, offering voice cloning from as little as 1 minute of audio, an extensive pre-built voice library, explicit emotional range controls, and a developer-grade API. It is best suited for audio-focused use cases (podcasts, audiobooks, voiceovers) rather than video dubbing workflows where lip-sync is required.
CAMB.AI differentiates with its proprietary MARS voice synthesis engine, which claims industry-leading emotional transfer accuracy and is built specifically for cinematic and professional media production. Teams dubbing documentary, narrative, or live-event content — where preserving the emotional tenor of the original performance is critical — should evaluate CAMB.AI alongside VideoDubber.ai.
Voice cloning output quality is primarily determined by three factors: the quality of the source audio, the architectural sophistication of the model, and the linguistic complexity of the target language. Of these, source audio quality is the single factor most within the user's control and has the largest impact on results — a state-of-the-art model fed poor audio will consistently underperform a simpler model fed clean, high-quality recordings. Teams that invest time in proper audio capture see disproportionate improvements in output quality.

Source audio quality tiers — hitting the "recommended" column (44.1kHz, 24-bit, 35dB+ SNR, 30s+ duration) produces dramatically better cloning output.
| Audio Specification | Minimum | Recommended | Professional |
|---|---|---|---|
| Sample rate | 16kHz | 44.1kHz | 48kHz |
| Bit depth | 16-bit | 24-bit | 24-bit |
| SNR (signal-to-noise) | >20dB | >35dB | >40dB |
| Duration (zero-shot) | 3–5 sec | 30 sec–1 min | 2–5 min |
| Duration (fine-tuned) | 1 min | 5–10 min | 15+ min |
The cloneability of a voice also matters. Clear, distinct voices with consistent speaking patterns and moderate pacing are easiest to clone with high fidelity. Voices with heavy accents, highly variable speaking pace, very soft volume, or frequent non-speech sounds (throat clears, breathing) are harder to capture reliably. In practice, a professional presenter speaking at a comfortable pace in a well-equipped recording environment will clone better than an informal screen recording from a laptop microphone.
For optimal results, record source audio in a quiet, acoustically treated space using a professional-grade microphone (cardioid condenser or dynamic). Speak naturally — avoid reading scripts in a flat, unnatural cadence, since the TTS model learns prosody from your samples and will reproduce whatever rhythm and energy you captured. Include variety: questions, statements, and some emotional variation help the encoder build a more robust voice representation. After cloning, always validate by listening to the generated output alongside the original recording and checking for artifacts, unnatural pauses, or tone drift, especially at sentence boundaries.
Despite rapid progress, AI voice cloning for video dubbing faces several real-world limitations. Emotional accuracy remains the hardest problem: while modern systems can replicate the speaker's tonal quality, transferring nuanced emotional performances — grief, sarcasm, irony, joy with specific intensity — across languages is still imperfect. Emotions are partly expressed through language-specific prosodic patterns, and a cloned voice synthesizing Spanish may not convey the same emotional weight as the original English performance, even if the voice timbre is accurate. Platforms explicitly trained on emotionally diverse multilingual data (like CAMB.AI's MARS engine) partially address this, but it remains a quality gap relative to human voice actors.
Language-specific challenges compound the issue: pronunciation accuracy in the target language, especially for languages with phonemes absent in the speaker's native language, requires dedicated training data and phonetic modeling. A native English speaker's cloned voice synthesizing Mandarin may carry subtle English phonetic patterns into the output unless the TTS model has been specifically trained to handle cross-lingual voice cloning with phoneme normalization. In practice, most platforms perform well on major European languages and Spanish/Portuguese but show more variance on languages like Arabic, Hindi, or tonal languages like Thai and Vietnamese.
AI voice cloning requires explicit consent from the voice owner. Using someone's voice to synthesize new speech without their knowledge or authorization violates both ethical norms and, increasingly, explicit legal requirements. The EU AI Act, U.S. state laws (including protections in California and New York), and platform terms of service all impose consent requirements. For video dubbing of the original speaker's own content, this is straightforward — the speaker is consenting to dub themselves. For third-party voice use, organizations need written consent agreements that specify usage scope, duration, and restrictions.
Misuse prevention is a serious concern: deepfakes, identity impersonation for fraud, and unauthorized content generation are all real risks. Responsible platforms implement watermarking (embedding an imperceptible acoustic signature in all generated audio for detection), usage monitoring for anomalous patterns, and strict identity verification for voice cloning access. Organizations using AI voice cloning should maintain clear internal policies on which voices may be cloned, who can initiate cloning jobs, and how generated audio may be used — treating voice data with the same sensitivity as biometric data.
The near-term roadmap for AI voice cloning is dominated by latency reduction. Current production systems typically require seconds to minutes to generate dubbed audio for a video clip. Emerging architectures — particularly non-autoregressive transformer models and distilled diffusion models — are pushing synthesis speeds toward real-time (generating 1 second of audio in under 100 milliseconds). This enables live dubbing for video calls, live-streamed events, and real-time interactive applications. Companies like Zoom and Microsoft Teams are actively researching real-time voice translation and cloning for cross-language communication, suggesting that live AI dubbing will be a mainstream feature within 2–3 years.
The hardest open problem — transferring emotional performance across language boundaries — is the focus of significant research. Multi-modal training approaches that jointly model audio, text, and facial expression are showing promise: by training on video data where the visual emotional signal provides additional supervision, models are learning more robust cross-language emotion transfer. Simultaneously, emotion-disentangled voice representations (architectures that separate speaker identity from emotional state in the embedding space) allow fine-grained emotional control at inference time — not just cloning the voice, but directing the emotional register of the synthesized speech independently.
The long-term trajectory of AI voice cloning extends into multimodal presence: combined voice, facial movement, and gesture synthesis that creates a complete digital representation of a person. Avatar-based video creation platforms are already integrating voice cloning with AI face generation to produce synthetic video presenters that look and sound like specific people in any language. Tools like VideoDubber.ai already represent an early stage of this integration by combining voice cloning with AI lip-sync. The next step is full avatar synthesis — generating the speaker's facial performance in the target language from scratch, not just adjusting the original video. This has profound implications for global content production: a single recording could become the source for unlimited localized video versions, each with natural visual lip movements in the target language.
Zero-shot voice cloning systems like those in VideoDubber.ai and ElevenLabs can produce acceptable results from as little as 3–10 seconds of clean audio, though 30 seconds to 1 minute delivers significantly better quality. Fine-tuned systems require 1–15 minutes of audio. For professional-grade results where voice fidelity is critical, 5–15 minutes of high-quality recorded speech provides the best foundation.
Traditional text-to-speech uses a single generic synthetic voice that sounds the same for every user. AI voice cloning for dubbing extracts a specific speaker's unique vocal identity — their timbre, cadence, accent, and emotional register — and uses it to condition every syllable of generated speech. The output sounds like that speaker recorded the translated content themselves, not a generic synthetic voice reading a script.
For most business and content creation use cases — corporate training, online courses, marketing videos, product tutorials, customer support content — AI voice cloning dubbing now meets professional quality standards, according to user testing across platforms like VideoDubber.ai and ElevenLabs. For premium entertainment content (films, major TV productions), where nuanced actor performance is part of the product, traditional dubbing with human voice actors still holds an edge in emotional authenticity, though that gap is narrowing rapidly.
Leading platforms support between 30 and 150+ languages. VideoDubber.ai and Play.ht lead with 150+ languages. CAMB.AI covers 140+. ElevenLabs focuses on about 30 high-quality languages. Quality varies by language — major European languages, Spanish, Portuguese, and Japanese typically see the best results. Tonal languages and languages with complex phonemic systems (Mandarin, Arabic, Thai) require specialized model training and may show slightly lower fidelity.
AI lip-sync works by analyzing the speaker's facial movements frame by frame and then adjusting either the audio timing or the video's visual lip movements to match the newly synthesized audio. Advanced implementations — like those in VideoDubber.ai — actually modify the lip movements in the video using generative AI so that the speaker's mouth appears to be naturally speaking the dubbed language, not just the original language sped up or slowed down. This produces significantly more natural results than simple audio timing adjustment.
Cloning your own voice to dub your own content is straightforwardly legal and ethical. Cloning another person's voice requires their explicit written consent specifying the scope and duration of use — many jurisdictions now mandate this legally, including under the EU AI Act and various U.S. state biometric data protection laws. Unauthorized voice cloning for impersonation, fraud, or deepfake creation is illegal in most jurisdictions and violates all major platform terms of service. Responsible use means obtaining consent, maintaining records of that consent, and using platforms with built-in misuse detection.
AI voice cloning preserves the speaker's baseline vocal characteristics — tone, pitch range, speaking pace — which carries significant emotional information from the original performance. However, transferring nuanced emotion across language boundaries (especially complex affects like sarcasm, irony, or layered grief) is still imperfect. Platforms explicitly trained on multilingual emotional data (CAMB.AI's MARS engine) perform better on emotional accuracy. For most informational video content, AI dubbing's emotional accuracy is sufficient; for highly performative or narrative content, reviewing and adjusting synthesized audio is recommended.
Traditional professional dubbing costs $2,000–$15,000+ per language per hour of content, depending on market, voice actor rates, and studio costs, according to localization industry benchmarks. AI voice cloning dubbing on platforms like VideoDubber.ai costs a fraction of that — typically $10–$100 per language for the same content. At 10 languages, that difference compounds to $20,000–$145,000 per project. For organizations with large or frequently updated video libraries, the cost advantage of AI dubbing is transformative.
Start dubbing your videos in 150+ languages with VideoDubber →

With a background in AI and a passion for clear technical communication, I enjoy breaking down complex tools and processes. Exploring new software and sharing insights is a key focus.
Voice cloning explained: how AI replicates any voice from 3 seconds of audio. Best 2026 models, pricing comparison, ethical guide, and use cases.
Learn what video translation and AI dubbing are, how they work, and why VideoDubber.ai is the best solution for translating videos while preserving voice, tone, and emotion. Complete guide covering benefits, use cases, and best practices.