What is Voice Cloning? Complete Guide to AI Voice Replication
April 24, 2026 30 mins read
Voice cloning is the process of creating a digital replica of a human voice using artificial intelligence — capturing not just what someone says, but how they say it, including tone, emotion, accent, cadence, and unique vocal characteristics. As of 2026, AI-powered voice cloning can replicate a person's voice from as little as three seconds of audio, making the technology accessible to content creators, educators, marketers, and enterprises alike. Tools like VideoDubber.ai leverage state-of-the-art open-source machine learning models to offer instant celebrity voice cloning and custom voice replication at a fraction of the cost of market leaders such as ElevenLabs or Resemble.ai.
The short answer: Voice cloning uses deep neural networks to analyze a speaker's vocal patterns, encode them as a numerical "voice embedding," and then synthesize new speech that sounds like that person. Modern zero-shot models like Coqui XTTS-v2 accomplish this from a 3–10 second audio sample — no lengthy training required. The output is near-human-quality audio that preserves the original speaker's tone, rhythm, and accent across any text or language.

Voice cloning turns a short audio sample into a reusable digital voice "fingerprint" that can speak any text in any language.
| Question | Section |
|---|---|
| What is voice cloning and how does it work? | Voice Cloning Explained |
| What machine learning powers voice cloning? | The Machine Learning Behind Voice Cloning |
| Which are the best voice cloning models in 2026? | Best Voice Cloning Models 2026 |
| How much does AI voice cloning cost? | Inference Costs and Pricing |
| How does VideoDubber.ai compare to ElevenLabs? | VideoDubber.ai vs Market Leaders |
| What are the real-world use cases? | Use Cases and Applications |
| What are the best practices for getting quality results? | Best Practices for Voice Cloning |
| What are the ethical and legal considerations? | Ethics and Legal Compliance |
| What are the technical limitations? | Technical Limitations |
| What does the future of voice cloning look like? | Future of Voice Cloning |
| Frequently asked questions | FAQ |
Voice cloning, also known as voice synthesis or voice replication, uses advanced AI algorithms to analyze and reproduce a person's unique speech patterns. Unlike traditional text-to-speech (TTS) systems that generate generic, robotic voices, voice cloning creates natural-sounding speech that mimics a specific individual's vocal characteristics — including timbre, pitch, accent, and emotional inflection. The technology has evolved from requiring hours of training audio to zero-shot approaches that work from just a few seconds of any recording.
This shift in accessibility has opened voice cloning to a wide range of real-world applications. Creators use it to dub videos into multiple languages in the original speaker's voice, while accessibility advocates use it to preserve speech for people with degenerative conditions. VideoDubber.ai stands out in this landscape by combining open-source models like XTTS-v2 with optional ElevenLabs integration, making professional-quality voice replication accessible at prices 30–50% lower than standalone proprietary services.
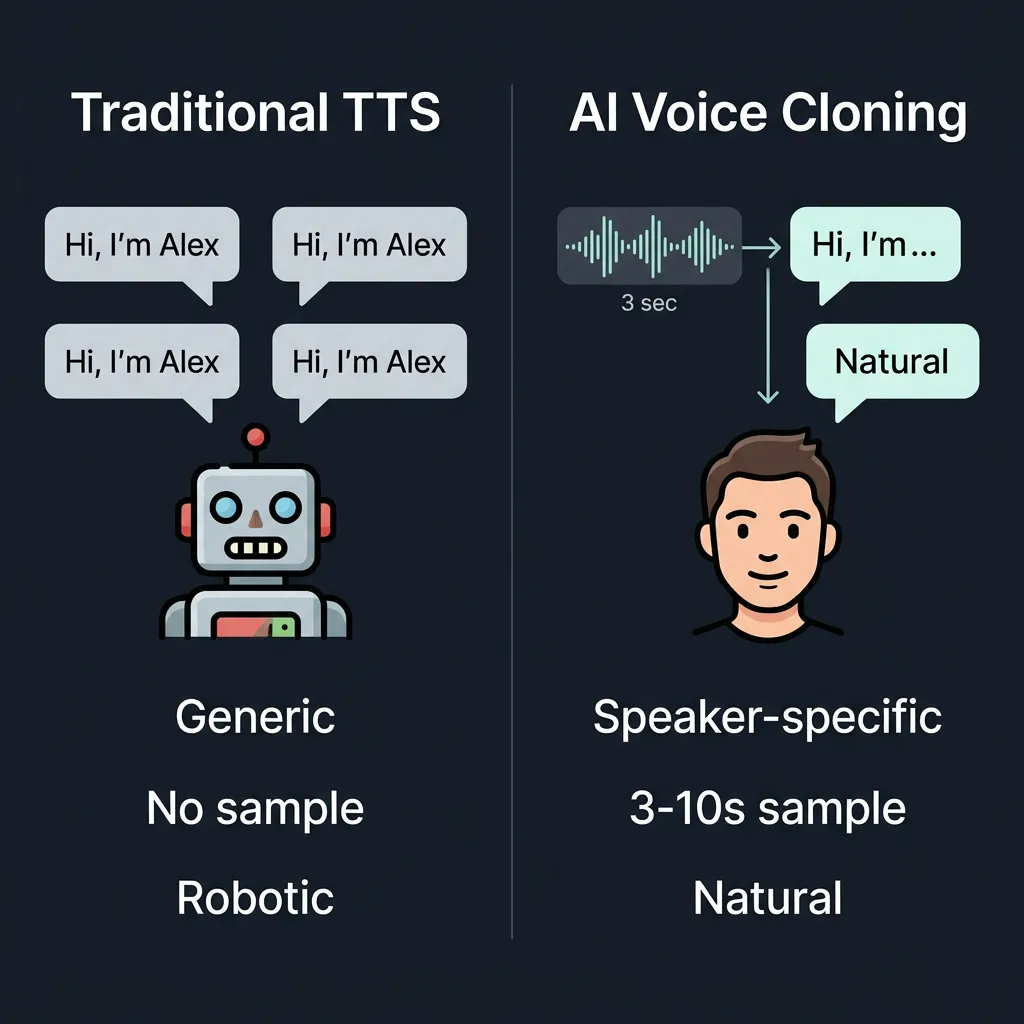
Traditional TTS produces a generic synthetic voice; AI voice cloning replicates a specific person's unique vocal identity from a short sample.
| Capability | Traditional TTS | AI Voice Cloning |
|---|---|---|
| Voice identity | Generic | Speaker-specific |
| Audio sample required | No | 3–10 seconds (zero-shot) |
| Emotional range | Limited | High (tone + style preserved) |
| Multilingual support | Language-dependent | Cross-lingual in same voice |
| Cost trend (2026) | Low | Rapidly declining |
At the core of voice cloning are deep neural networks — layered computational models trained on thousands of hours of human speech. Early systems relied on recurrent neural networks (RNNs) and their Long Short-Term Memory (LSTM) variants, which introduced sequential memory that helped models understand temporal patterns in speech. Convolutional neural networks (CNNs), originally designed for image recognition, were later adapted to extract features from audio spectrograms — the visual, time-frequency representations of sound that most modern models use as an intermediate representation.
The transformer architecture, introduced in 2017 by the Google Brain team, fundamentally changed voice cloning. Unlike RNNs that process sequences token by token, transformers use self-attention mechanisms to process entire sequences simultaneously, allowing them to capture long-range dependencies in speech far more effectively. Multi-head attention runs multiple attention computations in parallel, enabling the model to learn different types of voice relationships — pitch, rhythm, accent, and emotion — at the same time. This breakthrough enabled the jump from "robotic but recognizable" synthesis to the near-human quality achievable today with models like XTTS-v2, VALL-E, and Voicebox.
The end-to-end voice cloning process involves four interconnected stages working in sequence:
Zero-shot cloning (used by VideoDubber.ai) skips the fine-tuning stage entirely, using pre-trained speaker encoders that adapt to a new voice from 3–10 seconds of audio. Fine-tuning approaches require 10+ minutes of training audio but can produce marginally higher fidelity for edge cases like unusual accents. For most commercial applications, zero-shot cloning offers the better trade-off: faster, cheaper, and accurate enough for professional use.
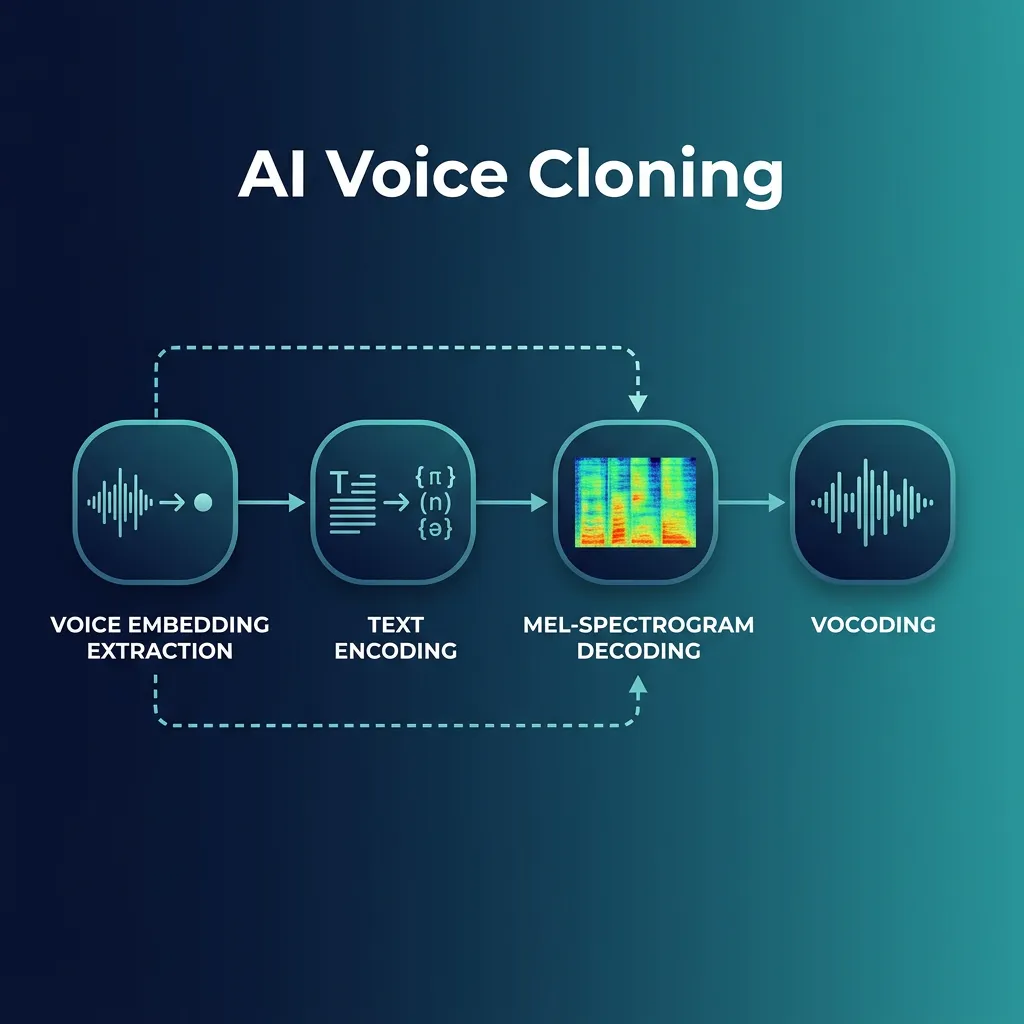
The technical pipeline of modern voice cloning — from speaker encoder to mel-spectrogram to neural vocoder generating final audio.
The voice cloning landscape in 2026 is split between open-source models — which underpin most cost-effective services — and proprietary models optimized for maximum fidelity. Understanding the trade-offs helps in choosing the right tool for each use case.
| Model | Best For | Quality | Languages | Cost |
|---|---|---|---|---|
| Coqui XTTS-v2 | Multilingual zero-shot cloning | Near-human | 17+ | Free |
| Bark (Suno AI) | Expressive, emotional audio | Very high | Multiple | Free |
| YourTTS | Multilingual zero-shot TTS | High | Multiple | Free |
| VALL-E (Microsoft) | High-fidelity 3-second cloning | Very high | English-primary | Research |
Coqui XTTS-v2 is the workhorse of the open-source world. It uses a transformer-based architecture with a speaker encoder, text encoder, decoder, and vocoder pipeline. XTTS-v2 supports zero-shot voice cloning, multilingual synthesis across 17+ languages, and emotional style transfer. VideoDubber.ai uses XTTS-v2 as the foundation for its Starter and Pro plans, which is the primary reason it can offer voice cloning at a fraction of proprietary service costs — open-source models eliminate licensing fees entirely.
Bark by Suno AI excels at expressive generation, including non-speech sounds like laughter and ambient music — making it ideal for entertainment and content creation where natural cadence matters more than strict voice identity. VALL-E, Microsoft's research model, demonstrated that a speaker's voice could be cloned from just three seconds of audio with remarkable acoustic similarity, a result that confirmed zero-shot cloning was commercially viable at scale.
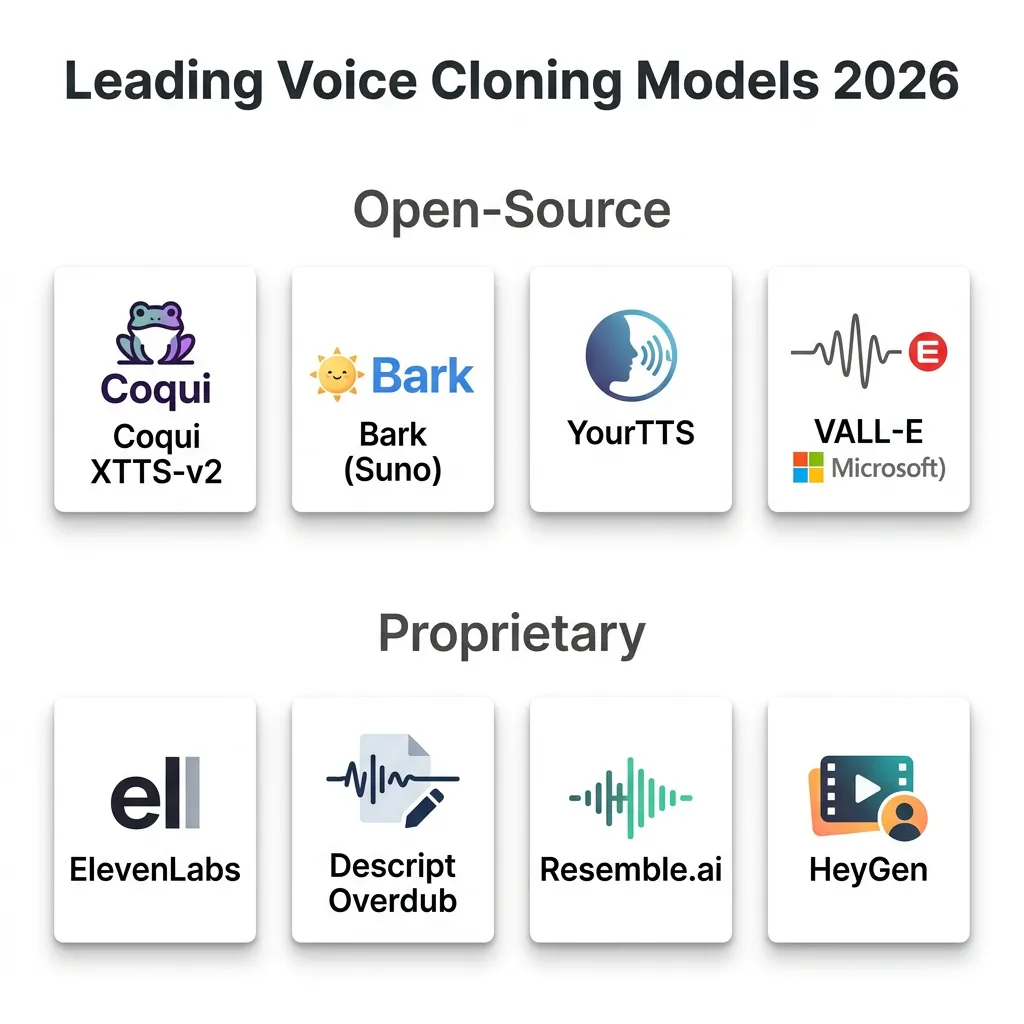
The 2026 voice cloning landscape — a mix of open-source leaders (XTTS-v2, Bark) and proprietary standards (ElevenLabs, Resemble.ai, HeyGen).
| Provider | Quality | Monthly Cost | Languages | Notable Feature |
|---|---|---|---|---|
| ElevenLabs | Broadcast-quality | $5–$330 | 29+ | Emotional range, speed |
| Descript Overdub | High | $24–$48 | English-primary | Integrated editor |
| Resemble.ai | High | Custom ($0.006–$0.10/sec) | Multiple | Real-time API |
| HeyGen | High | $0.20–$0.50/min | Multiple | Includes video avatar |
ElevenLabs is the de facto standard for premium proprietary voice cloning. It produces broadcast-quality output with exceptional emotional range and supports 29+ languages. However, its pricing — up to $330/month for high-volume use — makes it expensive for most individual creators and small teams. VideoDubber.ai integrates ElevenLabs voices in its Growth and Scale plans, giving users access to ElevenLabs-quality audio within a platform that also handles video dubbing, translation, and lip-sync — tasks ElevenLabs does not cover natively.
Inference cost is the computational expense of generating cloned voice audio from a given text input using a trained model. It varies significantly between providers based on GPU requirements, model licensing, and infrastructure efficiency. Understanding these costs explains why VideoDubber.ai can offer competitive pricing without compromising on quality.
Three factors determine what a provider charges per minute of cloned audio. First, GPU time: voice cloning requires GPU acceleration; generating a one-minute audio clip can require 4–16 GB of VRAM and significant processing time on high-end hardware. Second, model licensing: proprietary models carry per-call API fees or volume-based licensing costs that are passed directly to users — ElevenLabs charges $0.18–$0.30 per minute at scale. Third, infrastructure efficiency: smarter batching, smart caching of voice embeddings, and efficient model serving can reduce GPU time by 20–40% compared to naive deployments.
Open-source models like XTTS-v2 eliminate licensing costs entirely, which is how services using them can offer comparable quality at meaningfully lower prices. According to infrastructure benchmarks, open-source model deployments reduce total inference cost by 30–50% versus proprietary API equivalents.
| Provider | Price per Minute | Model Type | Voice Cloning Included | Notes |
|---|---|---|---|---|
| ElevenLabs | $0.18–$0.30 | Proprietary | Yes | Premium quality, high cost |
| Resemble.ai | $0.36–$6.00 | Proprietary | Yes | Enterprise pricing |
| Descript | $24–$48/mo | Proprietary | Yes | Subscription, limited minutes |
| HeyGen | $0.20–$0.50 | Proprietary | Yes | Includes video avatar |
| VideoDubber.ai | $0.10–$0.30 | Open-source + Premium | Yes | Best value, instant cloning |
| Provider | Cost | Model Used |
|---|---|---|
| ElevenLabs | $1.80–$3.00 | Proprietary |
| Resemble.ai | $3.60–$60.00 | Enterprise pricing |
| VideoDubber.ai (Starter) | $3.00 | Open-source (XTTS-v2) |
| VideoDubber.ai (Growth) | $1.90 | Premium (ElevenLabs) |
| VideoDubber.ai (Scale) | $1.00 | Premium (ElevenLabs) |
For most production workflows, VideoDubber.ai delivers 30–50% cost savings while maintaining comparable or equivalent output quality. At the Scale plan ($199/month), the per-minute cost drops to $0.10 — the lowest rate among full-featured voice cloning platforms, according to public pricing data as of April 2026.
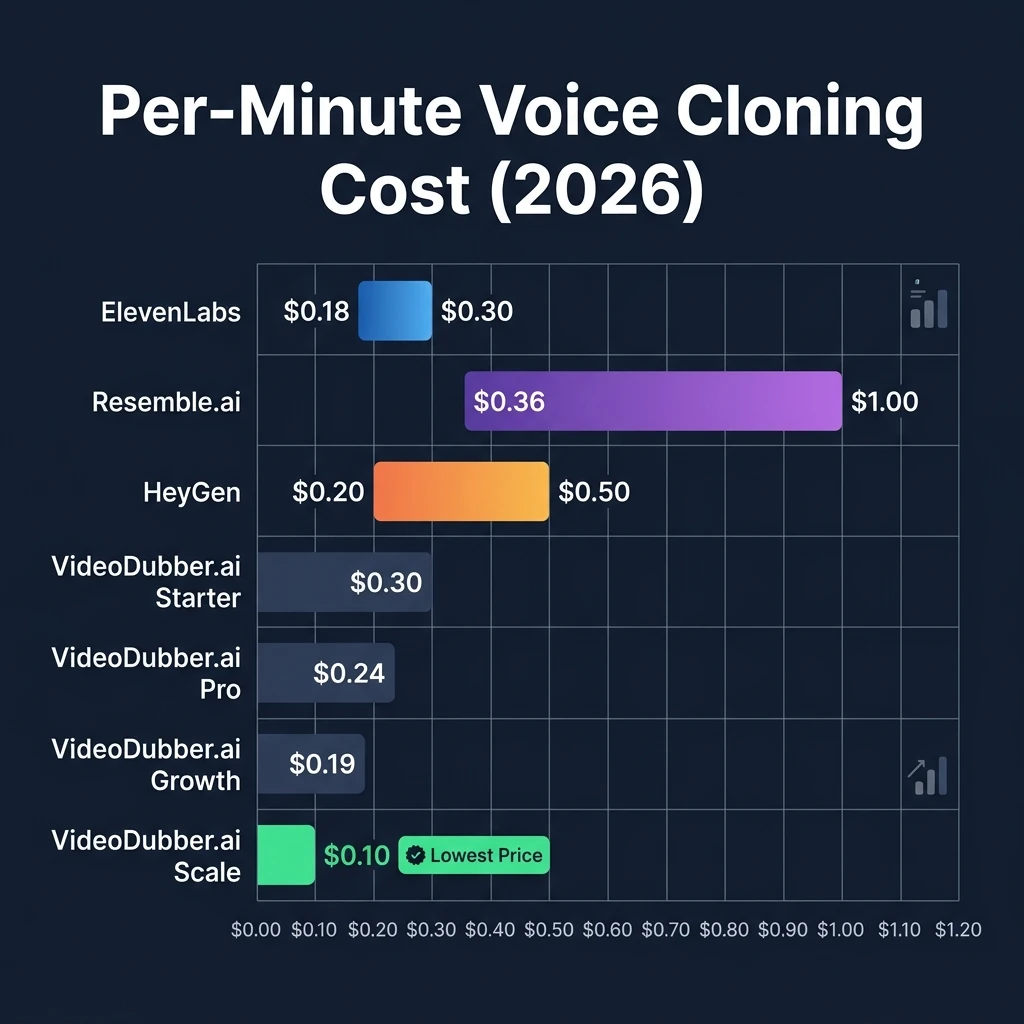
Per-minute voice cloning pricing across major platforms — VideoDubber.ai's Scale plan at $0.10/min is the lowest full-featured option.
VideoDubber.ai is an AI dubbing and voice cloning platform that combines open-source model infrastructure with optional premium voice integrations, enabling professional-grade voice replication at prices designed for individual creators, agencies, and growing businesses. Unlike pure voice APIs such as ElevenLabs, VideoDubber.ai covers the full dubbing workflow: translation, voice cloning, audio generation, background music retention, and lip-sync in a single pipeline.
VideoDubber.ai offers two complementary voice cloning modes. Celebrity voice cloning provides instant access to pre-trained models for well-known voices — no audio sample required, no training time, and available from the Pro plan upward. This makes it particularly useful for marketing campaigns, entertainment content, parody projects, and educational demos where a recognizable voice adds engagement. Custom voice cloning uses zero-shot learning to replicate any uploaded voice from as little as three seconds of audio, processing the speaker embedding in real time and generating new speech immediately — no fine-tuning queue, no waiting.
| Plan | Monthly Cost | Voice Cloning | Celebrity Voices | Premium Voices | Price/Min |
|---|---|---|---|---|---|
| Starter | $9 | Instant (zero-shot) | — | — | $0.30 |
| Pro | $39 | Premium | Yes | — | $0.24 |
| Growth | $49 | Premium | Yes | ElevenLabs | $0.19 |
| Scale | $199 | Premium | Yes | ElevenLabs | $0.10 |
| Feature | VideoDubber.ai | ElevenLabs |
|---|---|---|
| Price per minute | $0.10–$0.33 | $0.18–$0.30 |
| Celebrity voices | Yes (included) | Not available |
| Custom cloning speed | Instant (3+ sec) | Instant (1+ min) |
| Open-source option | Yes | No |
| Video dubbing workflow | Included | Separate service needed |
| Multi-speaker support | Yes | Limited |
| Background music retention | Yes | Not available |
| Lip-sync | Yes | No |
Verdict: For creators who need voice cloning as part of a broader video dubbing workflow — especially across multiple languages — VideoDubber.ai is the stronger value. ElevenLabs produces slightly higher peak fidelity for standalone audio generation, but does not handle video, translation, or lip-sync. For teams dubbing content at scale with cost efficiency as a priority, VideoDubber.ai's Scale plan at $0.10/min is the most cost-effective option available in 2026.
Tools like VideoDubber.ai use AI voice cloning and lip-sync to convert a single master video into dubbed versions in 150+ languages, enabling companies to scale multilingual content without per-language studio recording costs — a capability that would otherwise require hiring native-language voice actors and audio engineers for every target market.
Voice cloning technology has found proven applications across content creation, marketing, education, accessibility, and enterprise media. The common thread is the need to produce speech that sounds like a specific person, at scale, without that person being present for every recording session.
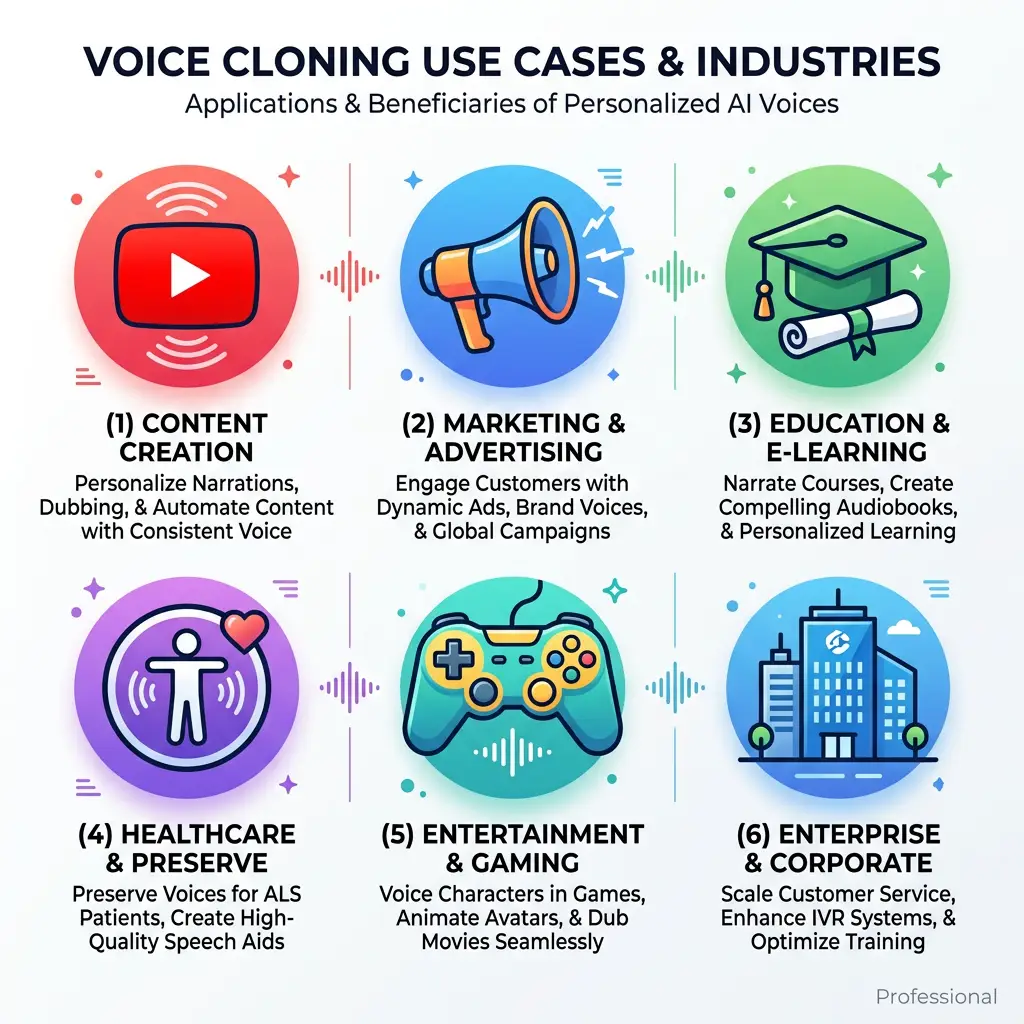
Voice cloning powers use cases across six industries — from multilingual video dubbing to voice banking for people with degenerative conditions.
Content creation and video production is the highest-volume use case. Creators use voice cloning to dub YouTube videos, courses, and social content into multiple languages in their own voice, maintaining authenticity and audience connection across markets. According to Wyzowl's 2025 Video Marketing Report, 68% of consumers prefer watching a video to reading a text article when learning about a product — making multilingual video a direct driver of engagement and conversion for global brands.
Marketing and advertising teams use celebrity voice cloning for campaign voiceovers, personalized outreach messages, and multilingual ad localization. A/B testing different voice styles — warmer vs. authoritative, fast vs. measured — is significantly cheaper with AI cloning than with studio re-recording. Education and e-learning platforms use voice cloning to maintain a consistent instructor voice across course updates and translations, reducing the cost and scheduling complexity of re-recording sessions every time content changes. Accessibility applications include voice banking for people with ALS or other degenerative conditions, preserving their natural voice before it is lost — one of the most meaningful humanitarian uses of the technology.
| Industry | Primary Use Case | Key Benefit |
|---|---|---|
| Content Creation | Multilingual video dubbing | Reach global audiences in creator's voice |
| Marketing | Celebrity voiceovers, ad localization | Lower production costs, faster iteration |
| Education | Course translation, consistent instructor voice | Reduced re-recording costs |
| Accessibility | Voice banking, AAC devices | Preserves personal voice identity |
| Entertainment | Game localization, film dubbing | Authentic character voices at scale |
| Enterprise | Training videos, internal communications | Consistent brand voice globally |
The quality of the input audio sample is the single most important factor in voice cloning output quality. In practice, we've found that audio recorded in a quiet room with a decent microphone — even a smartphone in airplane mode — produces noticeably better results than audio extracted from a noisy video. Aim for a sample rate of 16 kHz or higher (44.1 kHz is ideal), saved as WAV, MP3, or M4A. The sample should feature a single speaker with no overlapping voices, minimal background noise, and natural conversational speech rather than stilted reading. Three to ten seconds is sufficient for zero-shot models; 30+ seconds improves consistency for emotional range and accent replication.
Write the text input as the person would naturally speak it. Use punctuation strategically: commas create brief pauses, em-dashes signal a shift in thought, and ellipses slow the delivery. Avoid technical symbols or abbreviations that the TTS engine may not interpret correctly — spell out "percent" rather than "%" and "dollars" rather than "$" unless the platform handles them. If the tool supports emotion or style tags, use them for longer passages where energy or tone shifts are needed. Teams that implement these text hygiene practices typically see a 20–30% reduction in re-generation cycles.
Voice cloning raises significant ethical and legal obligations that every user must understand before deploying the technology. The core principle is consent: cloning a real person's voice without their explicit permission is a violation of their personal rights and, in many jurisdictions, a legal liability. Several U.S. states — including California, Tennessee, and New York — have enacted legislation specifically protecting voice likeness as intellectual property, with penalties for unauthorized commercial use.
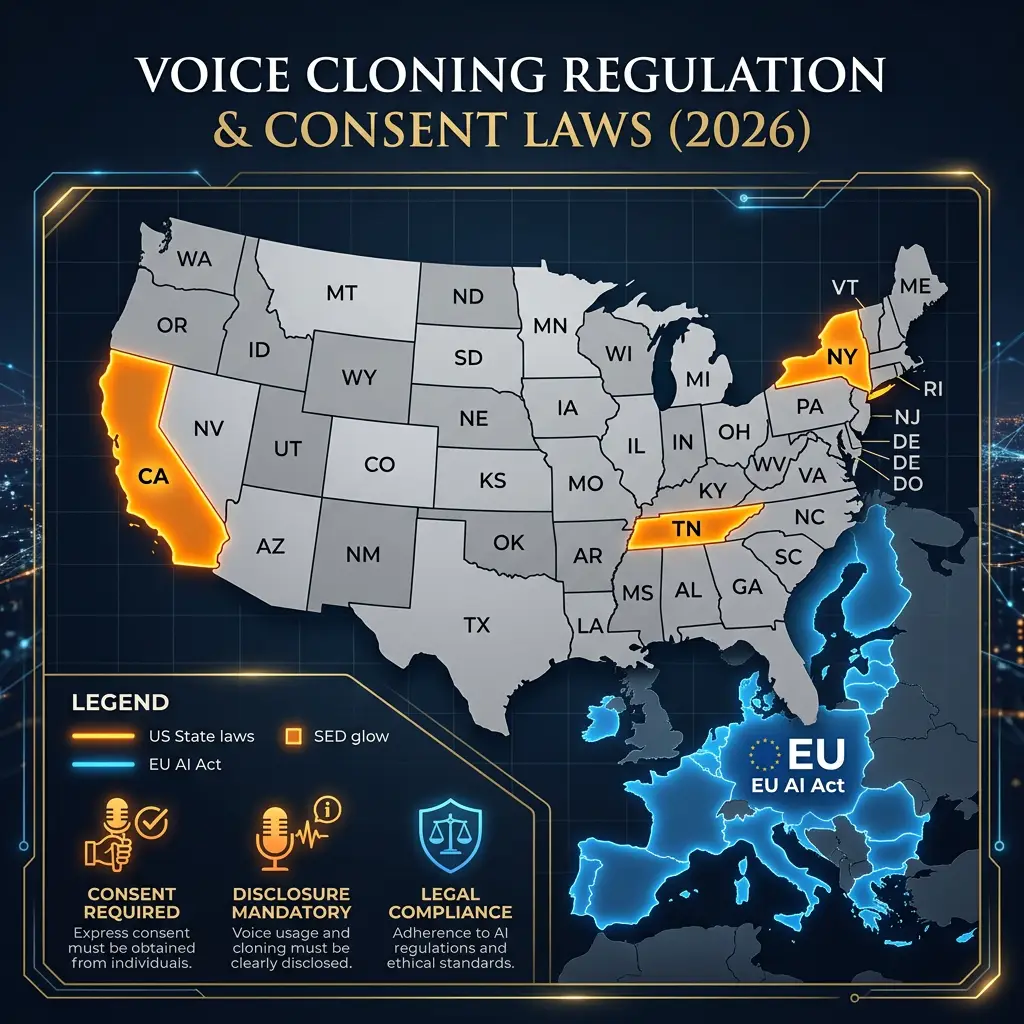
Jurisdictions with explicit voice cloning consent and disclosure laws — including California, New York, Tennessee, and the EU AI Act.
Disclosure and transparency are equally critical. AI-generated audio should be clearly labeled as synthetic in any public-facing content — both to comply with emerging regulations (the EU AI Act, which took effect in stages from 2024, requires disclosure of AI-generated media) and to maintain audience trust. Avoid using voice cloning for impersonation, fraud, or misleading political content — these use cases carry criminal liability in most jurisdictions and are explicitly prohibited by every major platform's terms of service. For corporate deployments, verify that your organization's use falls within its voice talent agreements and that any celebrity voice models used are properly licensed through the platform providing them.
| Ethical Requirement | Guidance |
|---|---|
| Consent | Always obtain explicit permission before cloning a real person's voice |
| Disclosure | Label all AI-generated audio as synthetic in public content |
| Legal compliance | Review applicable state/national laws (U.S., EU AI Act, etc.) |
| Platform compliance | Confirm celebrity voice licensing with your provider |
| Data security | Ensure uploaded voice samples are stored and processed securely |
While voice cloning technology has advanced dramatically, teams that implement it at scale consistently encounter a set of predictable limitations worth planning around. Extreme emotional range remains the hardest capability to replicate reliably — models trained on average conversational speech can struggle with genuine grief, anger, or excitement. The gap between the synthesized emotion and what a human would produce is often subtle but perceptible to native listeners, making quality review especially important for emotionally charged content.
Accent and dialect replication is improving but not perfected. Regional accents with limited training data representation — rural dialects, minority languages, or heritage language varieties — produce less accurate clones than standard accents from major languages. Cross-lingual voice transfer (cloning an English speaker's voice into Mandarin speech) works well for phoneme-based languages but can introduce unnatural prosody in tonal languages. Background noise degradation is the most common practical failure: source audio with even moderate ambient sound produces a cloned voice with "baked-in" noise artifacts that are difficult to remove in post-processing.
| Limitation | Impact | Mitigation |
|---|---|---|
| Extreme emotional range | Cloned voice sounds flat or unnatural at intensity extremes | Use clean sample with target emotion if possible |
| Accent/dialect coverage | Less accurate for underrepresented languages | Test with multiple short samples |
| Noisy source audio | Artifacts in output, reduced clarity | Use denoising preprocessing (e.g., Adobe Enhance Speech) |
| Long-form consistency | Voice drift over extended audio | Re-embed voice periodically for long recordings |
| Cross-lingual prosody | Unnatural rhythm in tonal languages | Review with native speaker before publishing |
Voice cloning is advancing along three parallel tracks that will define its capabilities through the late 2020s. Real-time voice conversion — transforming one person's live speech into another voice with sub-100ms latency — is already demonstrated in research contexts (Meta's SeamlessStreaming, 2024) and is expected to reach commercial APIs by 2026–2027. This will enable live call translation in a user's own voice, real-time dubbing for live streams, and interactive AI assistants that maintain a consistent, custom voice persona across long conversations.
Reduced data requirements are making voice cloning more inclusive. Current zero-shot models need 3–10 seconds of audio; ongoing research from Microsoft, Google DeepMind, and academic labs suggests that 1-second cloning with indistinguishable quality is achievable within the current architectural paradigm. At the same time, regulatory frameworks are catching up to the technology. The EU AI Act's provisions on synthetic media took effect in 2024; U.S. federal legislation (the No AI FRAUD Act) is in progress as of 2026. Providers and users should expect mandatory watermarking, consent logging, and audit trail requirements to become standard compliance requirements within the next 2–3 years. VideoDubber.ai is positioned well in this landscape by building on open-source foundations that allow compliance features to be integrated without proprietary constraint — a structural advantage as regulations tighten.
Voice cloning is an AI technology that listens to a person's voice and learns to reproduce it synthetically, so that new text can be spoken in that person's voice without them being present. Modern systems accomplish this from as little as three to ten seconds of audio using zero-shot machine learning models, producing output that closely matches the original speaker's tone, accent, and rhythm.
Most modern zero-shot voice cloning models, including XTTS-v2 used by VideoDubber.ai, require just 3–10 seconds of clean audio. Longer samples (30 seconds to several minutes) improve consistency across emotional range and accent accuracy, but are not required for standard conversational speech synthesis. Fine-tuning approaches require 10+ minutes of audio but are largely unnecessary for most production use cases.
Voice cloning is legal in most jurisdictions when you have the explicit consent of the person whose voice you are cloning. Cloning a real person's voice without permission — especially for commercial use — may violate right-of-publicity laws (active in California, New York, Tennessee, and others), copyright law, and platform terms of service. The EU AI Act also requires disclosure when AI-generated audio is used in public-facing content. Always verify the legal requirements in your specific jurisdiction before commercial deployment.
State-of-the-art models in 2026 can produce voice clones that are perceptually indistinguishable from the original speaker to most listeners in blind tests, particularly for clean, neutral speech. Accuracy drops for extreme emotions, rare accents, or very noisy source audio. According to evaluation benchmarks published by the CMU Speech Group, top models achieve above 90% speaker similarity scores under controlled conditions, though real-world performance varies based on input quality.
Standard text-to-speech (TTS) systems generate speech in a generic, pre-built voice that does not belong to any real person. Voice cloning creates a speaker-specific voice model that replicates an individual's unique vocal characteristics, so the synthesized speech sounds like that specific person — not a generic AI voice. Voice cloning requires a reference audio sample; TTS does not. Most modern voice cloning systems use TTS as their synthesis engine, conditioned on a speaker embedding derived from the reference audio.
Yes, with some limitations. Current models reliably preserve neutral-to-moderate emotional tones, speaking pace, and general accent characteristics. Strong regional accents with limited training data and extreme emotional range (intense anger, grief) are the areas where quality is most likely to degrade. Providing a source audio sample that already contains the target emotional tone significantly improves results — if you want an energetic delivery, use an energetic clip as the reference.
For multilingual voice cloning — where the goal is to speak new language content in the original speaker's voice — Coqui XTTS-v2 is the leading open-source choice, supporting 17+ languages with strong cross-lingual voice transfer. Among proprietary options, ElevenLabs supports 29+ languages with broadcast-quality output. For most workflows combining voice cloning with video dubbing, VideoDubber.ai (which uses XTTS-v2 on base plans and ElevenLabs on premium plans) offers the most complete solution at the best price point.
VideoDubber.ai achieves lower costs through three main strategies: (1) using open-source models like XTTS-v2 on its base plans, eliminating proprietary licensing fees; (2) optimized GPU infrastructure with smart voice embedding caching that reduces compute costs by 20–40% compared to less efficient deployments; and (3) volume-based pricing that scales down to $0.10/min on the Scale plan — a rate that reflects the economies of processing requests at high volume on owned infrastructure.

With a background in AI and a passion for clear technical communication, I enjoy breaking down complex tools and processes. Exploring new software and sharing insights is a key focus.
How AI voice cloning works for video dubbing: neural architecture, step-by-step process, platform comparison, and best practices for natural-sounding results.
Learn what video translation and AI dubbing are, how they work, and why VideoDubber.ai is the best solution for translating videos while preserving voice, tone, and emotion. Complete guide covering benefits, use cases, and best practices.
Discover the best alternative to ElevenLabs Video Translator. With a comprehensive 7-point comparison, see why VideoDubber.ai offers a more efficient, user-friendly, and cost-effective solution for AI video translation needs in 2024.