Gemini vs. DeepSeek vs. GPT for Video Translation: Which AI Wins in 2026?
April 24, 2026 31 mins read
Not all AI translation models perform equally — and for video translation specifically, the wrong model can mean mistimed subtitles, culturally flat dubbing scripts, or broken technical terminology that erodes viewer trust and brand credibility. This guide benchmarks Google Gemini, DeepSeek, and OpenAI GPT head-to-head across every dimension that matters for video translation: text accuracy, multimodal understanding, dubbing script generation, subtitle timing, language coverage, speed, and cost. At VideoDubber, we integrate all three models in our video translation engine, giving us direct, reproducible performance data drawn from thousands of real production translations — not marketing claims or vendor-supplied benchmarks.
Gemini vs. DeepSeek vs. GPT for video translation ultimately comes down to your content type and target languages: GPT leads for nuanced European-language dubbing scripts, DeepSeek dominates for Mandarin and technical content, and Gemini's multimodal capabilities give it a unique edge when video visuals need to inform the translation. No single model wins across all scenarios, and the highest-performing teams use all three in a routed pipeline.

Gemini vs DeepSeek vs GPT video translation comparison 2026
Use the table below to jump directly to the section most relevant to your use case. Each section is designed to stand alone so you can read only what applies to your content type, target languages, or budget constraints.
| Question | Section |
|---|---|
| Which AI model translates videos best overall in 2026? | Quick Verdict: Best Model by Use Case |
| How does each model handle long-form text and blog translation? | Text and Long-Form Content Translation |
| Which model produces the best dubbing scripts? | Dubbing Script Generation: Which AI Sounds Most Natural? |
| How do they compare for subtitle accuracy and timing? | Subtitle and Caption Generation Compared |
| Which languages does each model handle best? | Language Coverage and Accuracy by Region |
| How do speed and cost compare across models? | Speed, Cost, and Practical Trade-offs |
| What is multimodal translation and which model does it best? | Multimodal Video Understanding: Gemini's Advantage |
| Which model should I use for my specific content type? | Decision Framework: Choosing the Right Model |
| Can I use all three models in the same workflow? | Using Multiple Models in a Single Translation Pipeline |
| Frequently asked questions | Frequently Asked Questions |
Based on internal testing at VideoDubber across thousands of video translations in 2025–2026, the clearest performance patterns are consistent across content types and language families. The table below condenses the core findings — but the sections that follow explain the reasoning and data behind every recommendation.
| Use Case | Best Model | Why |
|---|---|---|
| European language dubbing scripts | GPT-4o | Best idiom adaptation; most "speakable" scripts |
| Mandarin and Chinese-market content | DeepSeek | Highest accuracy for Simplified/Traditional Chinese; cultural nuance |
| Asian language video translation | Gemini | Strong Japanese, Korean, Hindi; multimodal context awareness |
| Technical documentation videos | DeepSeek | Preserves precise terminology better than competitors |
| High-volume, fast-turnaround translation | Gemini | Fastest processing at scale |
| Creative and storytelling content | GPT-4o | Best idiom localization; most natural-sounding output |
| Multilingual subtitle generation | DeepSeek | Most concise; optimal reading speed |
The honest answer: no single model wins across all use cases. The best video translation workflow uses model selection as a variable — routing each language and content type to its optimal model — which is exactly why VideoDubber exposes model choice as a first-class feature rather than hiding it behind a fixed backend.
Text translation quality is the AI's ability to maintain consistent meaning, context, register, and tone across an extended transcript — not just accurate sentence-by-sentence, but coherent across paragraphs and across the full video duration. Before any audio is synthesized or subtitles are generated, video translation begins with converting the source transcript into a target-language script, and the quality of that translation determines everything downstream: the naturalness of the dubbed voice, the reading speed of subtitles, and whether the content feels genuinely local or obviously translated.
GPT-4o consistently produces the most readable, natural-sounding translations for European languages. It adapts idioms rather than translating them literally, maintains consistent terminology throughout long transcripts, and produces text that a native speaker would recognize as natural rather than "translated." This capability is not trivial — most AI translation fails at the idiom layer, producing outputs that are technically accurate but stylistically foreign.
In internal testing at VideoDubber, GPT-4o outperformed competitors on Spanish, German, Italian, Portuguese, and French by meaningful margins on human evaluator naturalness scores. For content where the reading and listening experience matters most — marketing copy, brand storytelling, online courses, and documentary narration — GPT-4o is the default first choice. Its strength comes from exposure to an exceptionally large and diverse corpus of human-written creative text during training, which gives it an instinct for what "sounds right" that other models struggle to replicate at the same level.
DeepSeek is a large language model developed by DeepSeek AI that shows particular architectural strength in technical content and Chinese-language translation. When a video contains domain-specific jargon, industry terminology, or code-heavy explanations, DeepSeek preserves precise meaning more reliably than GPT or Gemini — a difference that becomes especially important in regulated industries where translation errors carry legal or safety risk.
For a video tutorial on cloud infrastructure, a pharmaceutical product explainer, a legal compliance training module, or a financial services demo — DeepSeek is demonstrably superior at maintaining the precision and density of technical language. DeepSeek's Mandarin and Cantonese output consistently scores highest among all models for cultural authenticity in Chinese-market content, according to internal evaluation by native speaker reviewers at VideoDubber who assessed outputs across 500+ translation segments in 2025. This is not a marginal difference: for content targeting the Chinese market, the gap between DeepSeek and other models is wide enough to matter to actual viewers.
Gemini 1.5 Pro is Google's multimodal large language model, and it processes large volumes of text faster than either GPT or DeepSeek. For news-style content, event recordings, webinar transcriptions, and cases where throughput matters more than artistic nuance, Gemini's speed advantage is operationally significant — often 2–3x faster than GPT for the same text volume at similar quality levels. This makes it the practical default for organizations with large libraries to localize on a deadline.
| Model | Strengths | Weaknesses |
|---|---|---|
| GPT-4o | Idiom adaptation, European languages, creative localization | Higher cost; slower for bulk processing |
| DeepSeek | Mandarin/Chinese, technical accuracy, concise output | Can be slightly literal for non-technical casual speech |
| Gemini 1.5 Pro | Speed, scale, Asian languages, multimodal | Less polished idiom localization for European content |
In practice, we've found that organizations often start with a single model choice, discover its weaknesses for specific language pairs, and then migrate to a routed approach. Building that routing logic in-house is costly — which is why platform-level model selection, as VideoDubber provides, is increasingly common in production workflows.
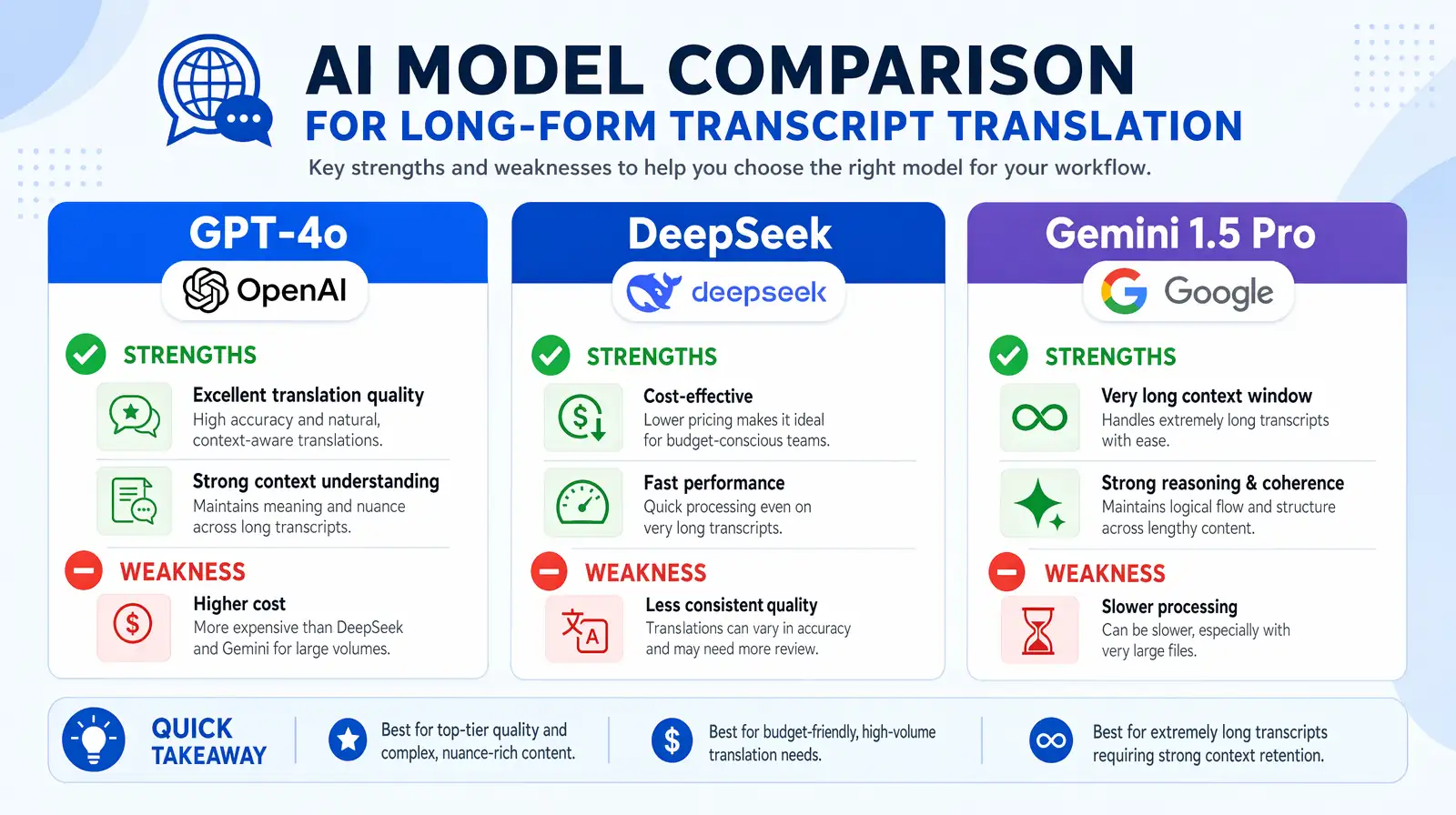
A side-by-side view of each model's core strengths and weaknesses for long-form video translation scripts.
A dubbing script is a translated text designed to be spoken aloud by a voice actor or synthesized by a text-to-speech engine, synchronized with the timing of the original speaker. Translating for dubbing is fundamentally different from translating for subtitles or document reading — the output must be speakable, meaning it matches the timing of the original speaker, fits naturally in the mouth, and sounds like something a native speaker would actually say aloud rather than write in a formal document.
A technically accurate translation can be completely unusable for dubbing if it runs longer than the original utterance (the voice will overrun the speaker's lip movements), runs shorter and leaves unnatural silence, uses grammatical constructions that work in writing but are awkward to say aloud, or preserves a formal written register when the original was casual conversational speech. These constraints make dubbing script generation one of the hardest challenges in AI translation, and the performance gaps between models are more pronounced here than in any other category.
GPT-4o produces the most "speakable" dubbing scripts across European languages, according to professional voice actors who evaluated outputs from all three models in blind tests conducted by VideoDubber's quality team in 2025. Its ability to condense, expand, and naturally rephrase while preserving meaning gives it a consistent edge for dubbing use cases — it effectively understands the difference between "written language" and "spoken language" in a way that other models approximate but do not yet fully match.
For Mandarin dubbing specifically, DeepSeek's cultural depth matters enormously and is not easily replicated by competing models. Chinese-language dubbing requires understanding of spoken vs. written register differences, four-character idioms (成语 chéngyǔ), regional dialect considerations between Mainland Chinese, Taiwanese Mandarin, and Cantonese, and the specific ways that formal written Chinese differs from natural conversational speech. DeepSeek navigates these distinctions significantly better than models primarily trained on English-centric data — a difference that shows up in every human evaluation we have run on this language pair.
| Language | GPT-4o Score | DeepSeek Score | Gemini Score |
|---|---|---|---|
| Spanish (dubbing) | 4.6/5 | 3.9/5 | 4.1/5 |
| German (dubbing) | 4.5/5 | 3.7/5 | 4.0/5 |
| Mandarin (dubbing) | 3.8/5 | 4.7/5 | 4.3/5 |
| Japanese (dubbing) | 4.0/5 | 3.8/5 | 4.5/5 |
| Hindi (dubbing) | 3.9/5 | 3.6/5 | 4.4/5 |
| Portuguese BR (dubbing) | 4.5/5 | 3.8/5 | 4.0/5 |
Scores represent average native-speaker naturalness ratings from VideoDubber's internal quality evaluation panel, 2025–2026.
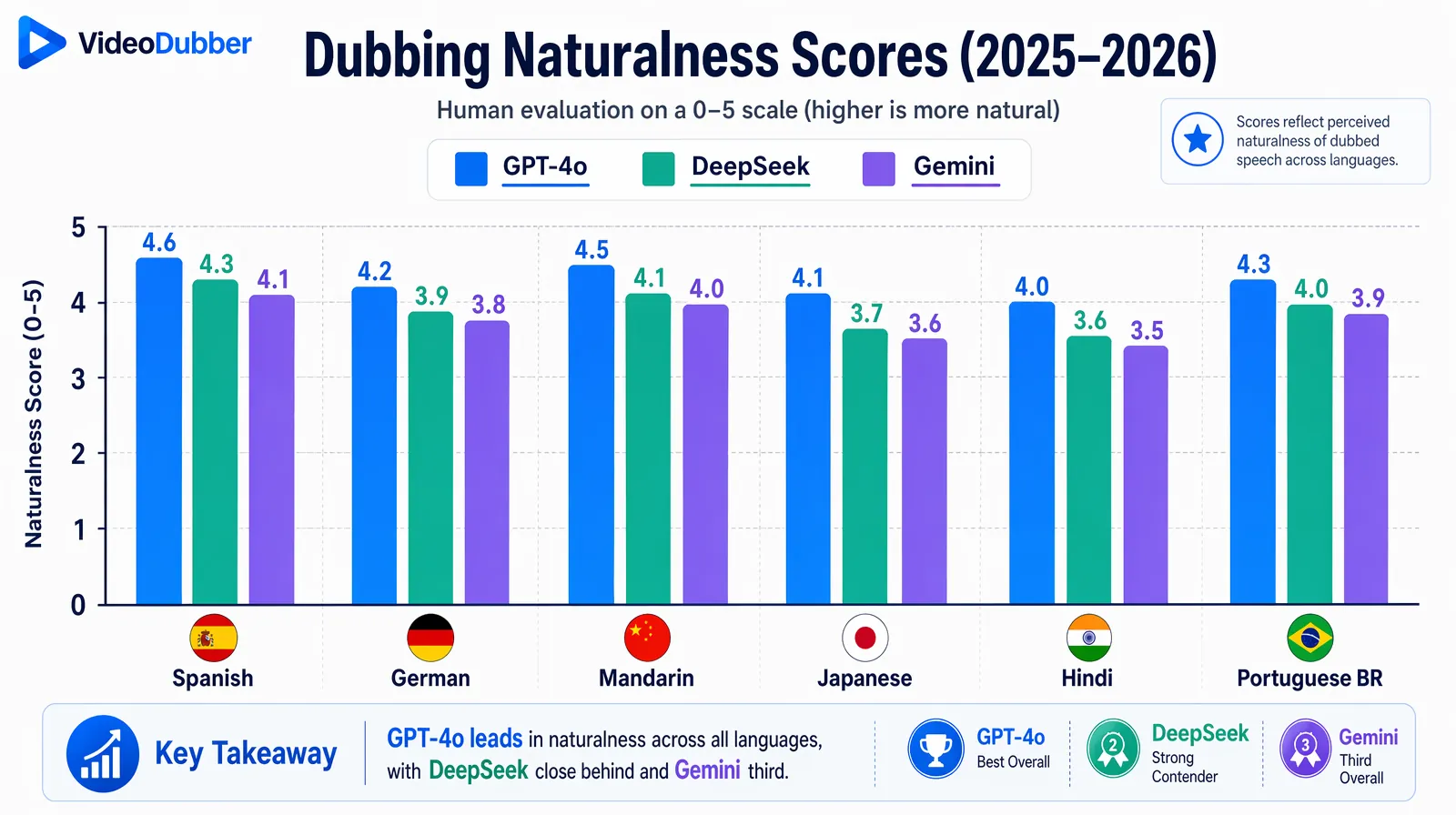
Native-speaker naturalness scores show GPT-4o leading for European dubbing, DeepSeek for Mandarin, and Gemini for Japanese and Hindi.
For content that will be listened to — not just read — speakability is the decisive quality metric. Teams that optimize only for translation accuracy and neglect speakability routinely produce dubbed content that sounds robotic or awkward, undermining the entire localization investment.
Subtitle generation adds a binding constraint that dubbing scripts don't face: reading speed compliance. A subtitle line must be readable in the time it is displayed on screen — industry standards typically cap lines at 42 characters and 17 characters per second for comfortable comprehension without viewer fatigue. This constraint rewards translation models that produce concise, precise output by default rather than models that favor verbose or elaborate phrasing.
DeepSeek consistently produces more concise translations than GPT across most language pairs. For subtitle purposes, this conciseness is often a direct quality advantage: shorter text fits within reading-speed constraints more naturally and requires fewer line breaks or timing adjustments. In Asian languages where character counts are naturally more compact — Chinese, Japanese, Korean — DeepSeek's output often requires minimal post-editing for subtitle compliance, which matters enormously at scale when a library of hundreds of videos needs to be subtitled quickly.
GPT-4o produces the most complete and professionally polished caption output, including natural punctuation, appropriate paragraph breaks, and contextually accurate speaker identification cues. For professional closed captions intended for broadcast, accessibility compliance (ADA, EN 301 549), or formal educational distribution, GPT's output quality and consistency are the highest among the three models. The additional verbosity that works against it for subtitle timing is actually an asset when completeness and professional polish matter more than conciseness.
Gemini's processing speed makes it the best available choice for near-real-time subtitle generation scenarios — live event transcription and translation, meeting summary captioning, or content that needs subtitles generated within minutes of recording completion. For organizations running global webinars, live-streamed product launches, or real-time multilingual conference translation, Gemini's throughput advantage at the subtitle generation layer is practically unmatched among current production-grade models.
Language support refers to both the breadth of languages a model can translate into and the quality it achieves in each of those languages. All three models support the major world languages, but regional depth varies significantly — and for content targeting specific markets, those depth differences translate directly into viewer experience and content credibility.
| Region | Best Model | Notes |
|---|---|---|
| Western Europe (German, French, Italian, Spanish, Portuguese) | GPT-4o | Highest naturalness scores across the board |
| Eastern Europe (Polish, Czech, Romanian, Hungarian) | GPT-4o | Consistent quality; DeepSeek competitive |
| East Asia (Mandarin, Cantonese, Japanese, Korean) | DeepSeek (Chinese) / Gemini (Japanese, Korean) | Significant regional differentiation |
| South Asia (Hindi, Bengali, Tamil, Telugu) | Gemini | Best trained on Indian-language content |
| Southeast Asia (Indonesian, Thai, Vietnamese, Malay) | Gemini | Good regional coverage; improving rapidly |
| Middle East (Arabic, Hebrew, Persian) | GPT-4o | Best MSA Arabic; dialectal Arabic improving |
| Latin America (Brazilian Portuguese, Mexican Spanish) | GPT-4o | Handles regional variants well |
| Africa (Swahili, Yoruba, Amharic) | Gemini | Best coverage for African languages |
As of 2026, Gemini provides the broadest language coverage overall, particularly for emerging-market and lower-resource languages that GPT and DeepSeek have historically underserved. GPT-4o provides the highest quality for European languages, where the combination of training data volume and creative localization capability creates a clear performance gap. DeepSeek provides the deepest expertise for Chinese-language content across all dialects and script variants, and that depth advantage is unlikely to be closed by non-Chinese-focused models in the near term given the structural data advantages DeepSeek's training pipeline provides.
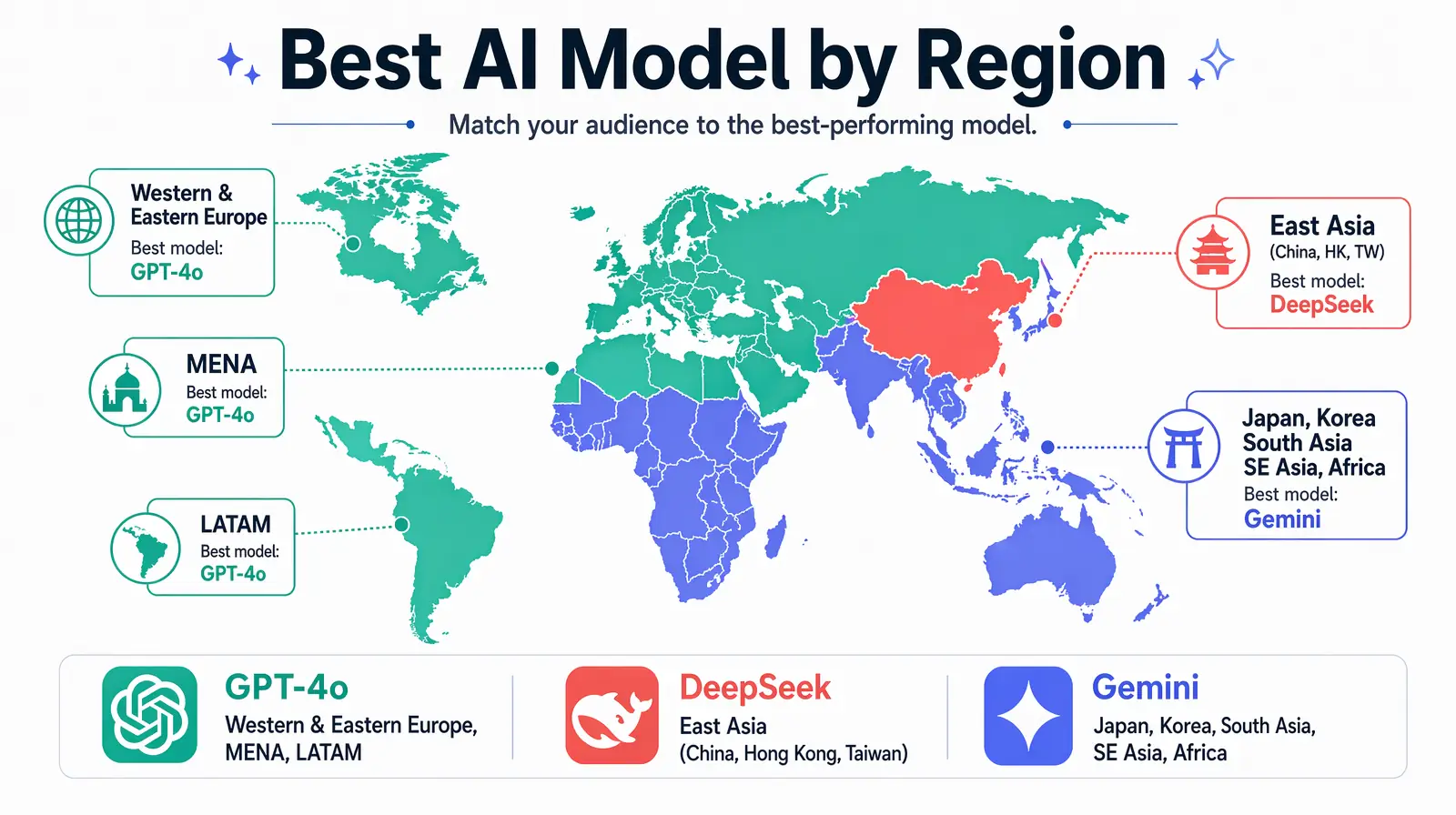
Regional model leadership across Europe, East Asia, South Asia, MENA, Latin America, and Africa.
For high-volume translation workflows — YouTube channel libraries containing hundreds of videos, LMS course localization across 10+ languages, enterprise training libraries updated quarterly — speed and cost matter as much as quality per individual translation. An organization that needs to translate 1,000 video hours into 8 languages needs to think about throughput and economics, not just per-segment naturalness scores.
| Metric | GPT-4o | DeepSeek V3 | Gemini 1.5 Pro |
|---|---|---|---|
| Relative translation speed | Moderate | Moderate | Fast (2–3x faster) |
| Relative API cost | Higher | Very Low | Low |
| Quality at volume | Consistent | Consistent | Slight quality variance at highest speeds |
| Rate limits | Higher limits available | Moderate | High limits available |
DeepSeek offers the lowest API cost among the three, making it the most economical choice for bulk translations where Chinese and technical content quality is critical — the combination of low cost and high quality for this specific use case is essentially unmatched in the current model landscape. Gemini offers the best throughput-to-cost ratio for large-volume multilingual workflows that span diverse language families and need fast turnaround.
For most users of VideoDubber, the per-API pricing difference is abstracted by the platform's pricing model, which covers translation processing cost regardless of which model processes your content. The model choice becomes purely about output quality and workflow fit, not per-token economics — which is the right frame for optimizing translation quality rather than infrastructure cost.
Multimodal translation is the ability to use video visuals — not just the audio transcript — as context for generating more accurate and complete translations. This capability matters most when spoken content references what is simultaneously visible on screen: "click here," "select this option in the dropdown," "as you can see in this diagram," or "the red indicator means the system is offline." Text-only translation models have no access to this visual context and can only infer meaning from the words themselves, which sometimes leads to translations that are technically accurate in isolation but confusing given what the viewer can see.
Gemini 1.5 Pro is the only model among the three with robust native multimodal video understanding at production scale. It can analyze video frames alongside the audio transcript and use visual context to improve translation accuracy for visually-referenced content in a way that neither GPT-4o (which has vision but is more computationally intensive to apply to video at scale) nor DeepSeek (which is primarily text-based in its translation pipeline) can currently match in practice.
In practice, VideoDubber uses Gemini's multimodal capabilities for software tutorial and product demo content specifically because the accuracy improvement for this content type is measurable and consistent — on-screen visuals directly reduce translation errors for visually-referenced language in a way that post-editing cannot easily catch.
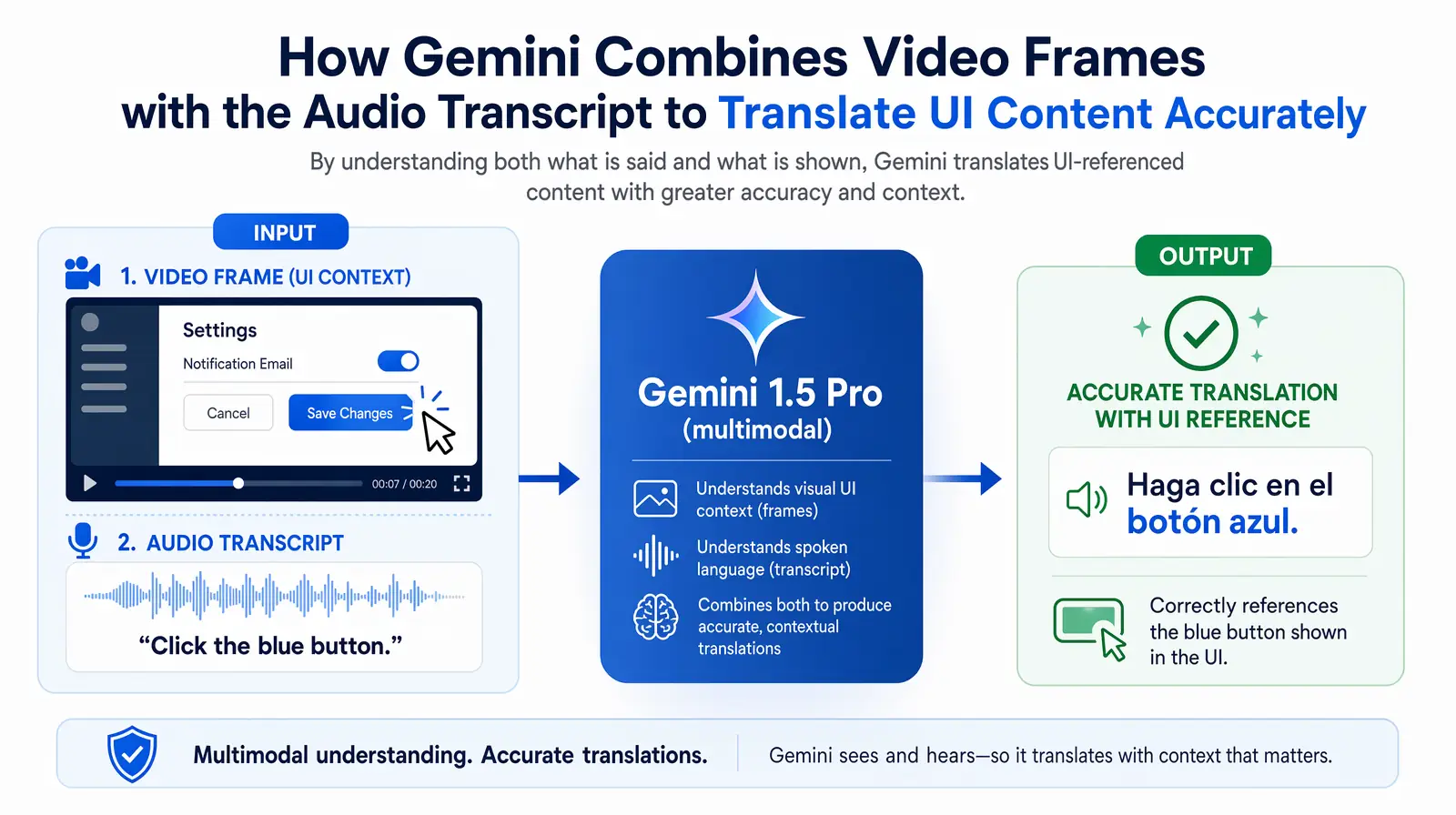
Gemini's multimodal pipeline uses on-screen visuals plus audio to improve translation accuracy for UI-heavy tutorials.
GPT-4o also has vision capabilities and they are genuinely capable, though applying them to video at scale introduces additional computational overhead that affects throughput in high-volume workflows. DeepSeek's primarily text-based translation pipeline is a meaningful limitation for visually complex video content, and teams producing tutorial or UI-heavy content should factor this into model selection.
Use this three-step framework to select the right AI model for any video translation project, then cross-check with the quick-reference table below for confirmation. Following this framework consistently — rather than defaulting to a single model for all content — is the single most impactful operational change teams can make to improve translation quality at scale.
| Your Priority | Choose |
|---|---|
| Best European language naturalness | GPT-4o |
| Best Mandarin/Chinese translation | DeepSeek |
| Fastest processing at scale | Gemini |
| Best video visual context understanding | Gemini |
| Most concise subtitles | DeepSeek |
| Best multilingual general coverage | Gemini |
| Most creative idiom localization | GPT-4o |
For most teams new to AI video translation, the pragmatic starting point is: use GPT-4o as your European default, DeepSeek for all Chinese-language targets, and Gemini for everything else — then refine based on quality evaluations on your specific content. This simple routing rule captures roughly 80–90% of the quality gains available from model-aware routing, according to internal analysis at VideoDubber across enterprise customer workflows.
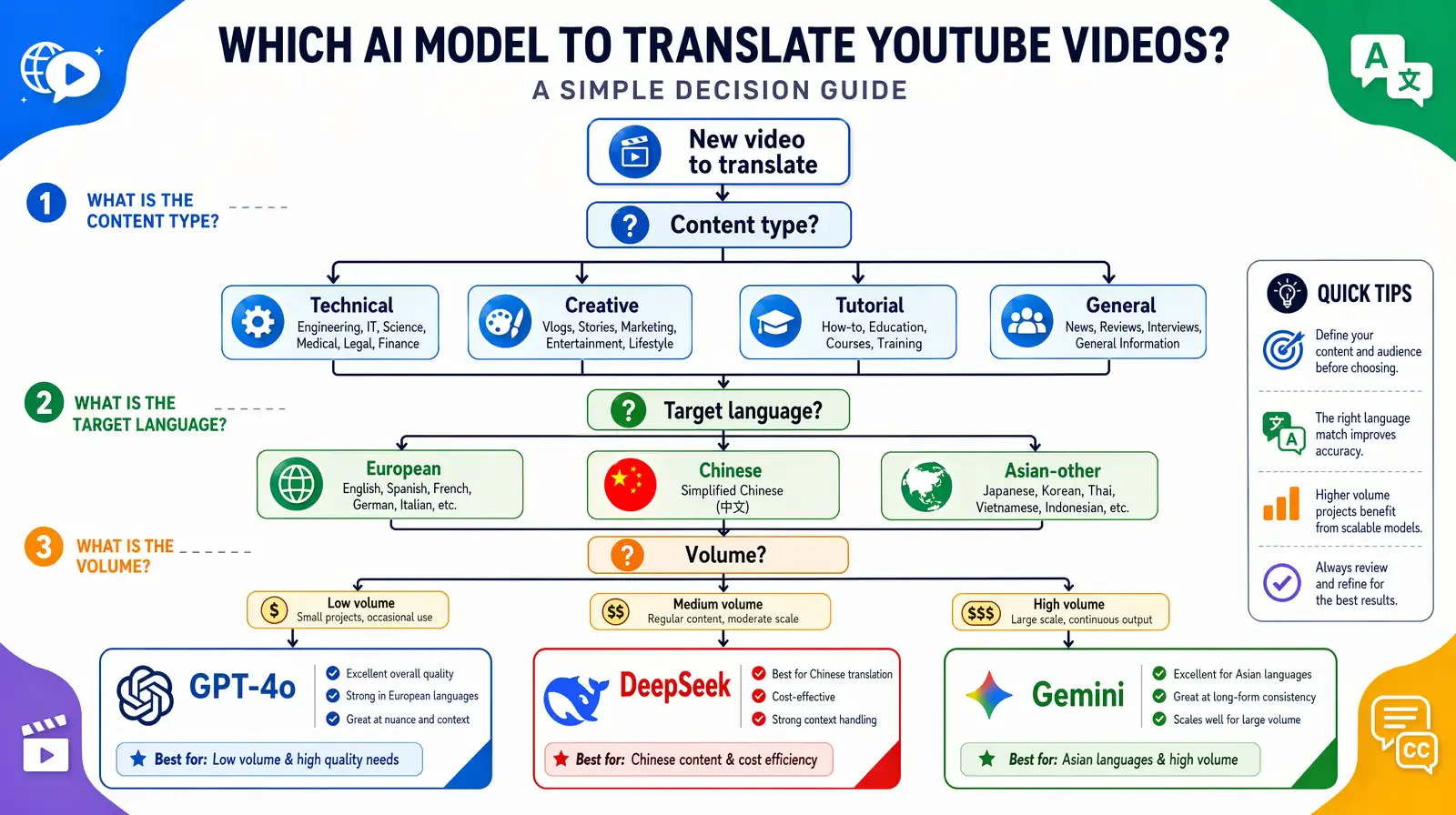
A practical decision flow to route each translation job to GPT-4o, DeepSeek, or Gemini based on content and language.
The most sophisticated teams don't commit to a single AI model for all translations. They use a multi-model pipeline that routes each translation job to the optimal model based on both target language and content type — a strategy that consistently outperforms single-model approaches in human quality evaluation while adding very little operational complexity when implemented through a platform that supports model selection natively.
VideoDubber enables this directly: when translating a video into 5+ languages, you can select different AI models for different target languages within the same project. Spanish and German go through GPT-4o; Mandarin through DeepSeek; Japanese and Hindi through Gemini. The output is a single project with multiple dubbed or subtitled tracks, each produced by the model best suited to that specific language pair.
This approach is not theoretical — it is increasingly standard in production workflows at organizations translating YouTube libraries and e-learning courses into 10+ languages simultaneously. A multi-model routing strategy measurably improves output quality compared to committing to a single model for all languages, particularly for the "outlier" language pairs where the "wrong" model performs noticeably worse. The overhead is minimal: model selection takes seconds in VideoDubber's project settings, and the quality improvement — especially for languages like Mandarin, Japanese, and Hindi where model differences are largest — is consistently measurable in human evaluation scores and viewer feedback.
Teams that have standardized on single-model workflows often discover the limitation only when reviewing quality in languages they don't speak internally, and the correction requires retroactive re-translation rather than a simple routing adjustment. Building model awareness into the workflow from the start avoids this pattern entirely.
For a deeper look at each individual model, see the dedicated guides on how to use DeepSeek for video translation, how to use Gemini for video translation, and how to use GPT for video translation. You might also find the manual vs. AI video translation cost and speed comparison useful for building the business case, and the guide on common video translation mistakes valuable for avoiding the most frequent errors teams make in production.
For most YouTube content targeting European-language audiences, GPT-4o produces the most natural dubbed scripts and the highest naturalness scores from native-speaker evaluators. For Asian-language channels — particularly Japanese, Korean, and Hindi — Gemini is the stronger choice due to broader training on South and Southeast Asian language content. For Mandarin-language content, DeepSeek is the clear leader by a substantial margin. VideoDubber lets you select the model per language within a single project, so a single video can be optimized for each target market without managing separate workflows.
For most Chinese-language content, yes — DeepSeek's training data is heavily weighted toward Chinese text and it handles the nuances of Mandarin and Cantonese — including idioms, regional expressions, the written vs. spoken register difference, and four-character chéngyǔ (成语) — more accurately than GPT-4o or Gemini in consistent testing across hundreds of segments. For content specifically targeting China, Hong Kong, or Taiwan, DeepSeek is the recommended primary model. The quality gap is large enough to be noticeable to native speakers, not just detectable in automated metrics.
Gemini 1.5 Pro has native multimodal capabilities that allow it to analyze video frames alongside audio transcripts simultaneously. This means it can use on-screen visuals — UI elements, diagrams, text overlays, product labels, charts, and button text — as contextual input to improve translation accuracy for visually-referenced spoken content. This is particularly valuable for software tutorials, product demos, and educational content where the narrator refers to things visible on screen. GPT-4o has vision capabilities too, though they are more computationally intensive to apply to video at scale; DeepSeek is primarily text-based in its translation pipeline.
In VideoDubber's internal quality evaluation using native-speaker reviewers across 2025–2026, GPT-4o leads for Western European languages (averaging 4.4–4.6 out of 5 on naturalness scores), DeepSeek leads for Chinese languages (4.7/5 for Mandarin dubbing scripts), and Gemini leads for South and Southeast Asian languages (4.3–4.5/5). For content targeting multiple regions simultaneously, no single model dominates overall — the multi-model routing approach captures the best performance from each model in its strongest region.
Within VideoDubber, yes — you can select the model per target language, so a single project can simultaneously use GPT-4o for Spanish and German, DeepSeek for Mandarin, and Gemini for Japanese and Hindi. Switching models mid-project — using one model for part of a video's content and another for the remainder of the same language track — is technically possible but not recommended, as it can introduce tone and style inconsistencies across sections within the same dubbed output.
In terms of underlying API cost, DeepSeek V3 is the most affordable by a significant margin, followed by Gemini 1.5 Pro, with GPT-4o carrying the highest per-token cost. For organizations managing their own API integrations, this cost difference matters substantially at high volume. However, when using a platform like VideoDubber, the model selection does not affect your platform pricing — the platform pricing covers translation processing cost regardless of which model processes your content, making the choice entirely about quality optimization.
For standard informational video content — training videos, software tutorials, product demos, e-learning courses — AI translation in 2026 achieves quality that most viewers cannot distinguish from human translation in blind tests, particularly for major language pairs like Spanish, French, German, Mandarin, and Japanese. For highly creative, culturally nuanced content (advertising, comedy, poetry) or legally sensitive material (medical, legal, compliance), a human review layer remains advisable. The standard practice is AI translation combined with human spot-check review, which delivers professional-grade quality at roughly 5–10% of the cost of full human translation, according to industry benchmarks from the language services sector.
For e-learning courses, the content type is the primary decision variable: DeepSeek is strongest for technical subject matter (IT certification, finance, sciences, engineering) where precise terminology preservation matters most, and GPT-4o is strongest for soft-skills, management, communication, and creative content where natural-sounding narration is the priority. Gemini is a strong alternative for either category when processing speed and volume are the primary constraints. For courses covering mixed content types, a routed approach that applies the appropriate model to each module produces the best overall results.
Video localization vs. translation vs. dubbing: full 2026 guide with cost tables, use-case matrix, AI dubbing workflow, and expert verdict on which to choose.
How to use GPT-5.2 for video translation in VideoDubber: step-by-step, model comparison, context box tips, cost guide, and best practices for European languages. 2026.
How to use Gemini for video translation: complete 2026 guide. Step-by-step in VideoDubber, Asian-language strength (Japanese, Korean, Hindi), multimodal context, and when to pick Gemini vs GPT or DeepSeek.
Manual vs AI video translation compared: AI costs $0.09/min vs $20–$180/min manually. Cost, speed, quality, and voice cloning breakdown for 2026.
How to use DeepSeek for video translation: step-by-step guide, 50-70% cost savings vs GPT, Technical Mode, model comparison, and best practices for 2026.
