Over 70% of content creators who need voiceover skip hiring a narrator—they use online text-to-speech tools instead. Converting text to speech online is fast, affordable, and no longer sounds robotic. Whether you need narration for a YouTube video, an e-learning module, a product explainer, or accessibility features, this guide covers everything: how it works, how to do it step by step, how much it costs, which tools to use, and how to get professional-quality results without a recording studio.
Text to speech (TTS) online means using a web-based tool or service to convert written text into spoken audio. You paste or type your script, choose a language and voice, and generate an audio file in seconds. Modern AI-powered online TTS delivers human-like intonation and supports dozens of languages, making it practical for professional voiceovers, training content, customer support narration, and multilingual dubbing at a fraction of studio cost.
As of 2026, online TTS typically costs $0.01–$0.10 per 1,000 characters or a few dollars per hour of audio—compared to $50–$200+ per minute for professional human narration. That 50–100x cost gap is why TTS has become the default for creators, platforms, and businesses that need scalable, multilingual audio output.
VideoDubber Text to Speech dashboard: convert text to speech online in 150+ languages.
What This Guide Covers
We answer the questions people actually search for when they want to convert text to speech online:
| Question | Section |
|---|---|
| What is text to speech and how does it work online? | What Is Text to Speech (TTS)? |
| Why use online TTS instead of a desktop app or studio? | Why Use Online Text to Speech? |
| How do I convert text to speech online step by step? | Step-by-Step: Convert Text to Speech Online |
| Is online TTS free or paid? How much does it cost? | Cost of Online TTS: Free vs. Paid |
| Online TTS vs. desktop vs. API—which should I use? | Online TTS vs. Desktop vs. API |
| What should I look for in an online TTS tool? | What to Look for in an Online TTS Tool |
| What are the best use cases for online TTS? | Use Cases: Videos, Audiobooks, E-Learning, Accessibility |
| How do I make TTS sound natural and professional? | Best Practices for Natural-Sounding TTS |
| TTS vs. voice cloning—what is the difference? | TTS vs. Voice Cloning: Which Do You Need? |
| Frequently asked questions about online TTS | Frequently Asked Questions |
What Is Text to Speech (TTS)?
Text to speech (TTS) is technology that converts written text into spoken audio using synthetic voices. Online TTS runs in the browser or via a web service: you supply the text, and the system returns an audio file (MP3 or WAV) that you can download, embed in a video, or use in apps.
Online TTS is powered by neural or AI voice models that produce natural prosody and pronunciation far beyond older concatenative or parametric synthesis systems. According to a 2025 assessment by Synthesys Research, AI-driven TTS now reaches near-human naturalness for 80%+ of major world language pairs and use cases—which is why it has become the default for creators and businesses building scalable audio content.
Voice synthesis is the broader technical term for generating speech from text or other non-audio input. Online TTS is one form of voice synthesis, delivered via the web without installation or hardware requirements. The technology has matured to the point where many listeners cannot reliably distinguish high-quality AI TTS from a professional voice actor in A/B tests.
How AI TTS Actually Works
Modern online TTS uses a three-stage neural pipeline:
- Text normalization: The system reads the input text, handles abbreviations, numbers, punctuation, and special characters to produce a clean pronunciation string.
- Acoustic modeling: A transformer-based neural network converts the normalized text into an intermediate acoustic representation (mel-spectrogram) capturing pitch, duration, and prosody.
- Vocoder synthesis: A neural vocoder (such as WaveNet or HiFi-GAN) converts the acoustic representation into a waveform—the final audio you hear.
The result sounds natural because the model learned from thousands of hours of real human speech recordings, capturing the rhythms and patterns of how people actually speak.
Why Use Online Text to Speech?
You do not need to install software or own expensive recording gear. Online TTS lets you convert text to speech from any device—laptop, tablet, or phone—with no setup. That is why it is the go-to for one-off voiceovers, rapid prototyping, and scaling narration across many languages without a per-language production team.
| Benefit | Why it matters |
|---|---|
| No installation | Start in seconds; no admin rights, no downloads, no license keys. |
| Cross-device | Same tool on desktop, tablet, and mobile; generate audio wherever you are. |
| Scalable | Generate hundreds of audio clips without booking a studio or scheduling voice talent. |
| Multilingual | One workflow for 50–150+ languages; no need to hire per-language narrators. |
| Cost-effective | Online TTS often costs a few cents to a few dollars per minute of audio, compared to $50–$200+ per minute for professional human narration. |
| Fast iteration | Change a word, regenerate in seconds; no re-booking a voice actor or resending files to a studio. |
For video dubbing, e-learning narration, and accessibility, online TTS is often the fastest and most affordable option. Tools like VideoDubber combine TTS with video localization so you can generate dubbed voiceovers and add multilingual audio tracks to existing videos in one seamless workflow.
Step-by-Step: Convert Text to Speech Online
Here is a concrete workflow that works for any online TTS tool. We use VideoDubber as the example because it is built for both standalone TTS and video translation and dubbing.
Step 1: Open the TTS Tool
Go to your chosen online TTS service. For VideoDubber: sign in at app.videodubber.ai and open the Text to Speech tool (or go directly to the TTS interface at Text to Speech).
Professional text-to-speech interface: input scripts and select from hundreds of diverse AI voice profiles.
Step 2: Enter Your Text
Paste or type the script into the text box. Keep paragraphs and punctuation clear—they help the AI with pacing and natural pauses. Use periods and commas where you want the narrator to pause. For long scripts, some tools support batch or chunked generation; break your content at logical section boundaries for easier editing later.
Step 3: Choose Language and Voice
Select the target language and then pick a voice. Most online TTS tools offer multiple voices per language (male/female, neutral/expressive, regional accent variants). Always preview a short sample before committing to a voice for a full project. The right voice match for your content type—formal for training, casual for vlogs—makes a significant difference in perceived quality.

Choose from a wide variety of AI voices including different genders, ages, and regional accents for 150+ languages.
Step 4: Adjust Speed and Prosody (Optional)
Many TTS tools let you control speaking rate, pitch, and emphasis. For e-learning narration, a slightly slower rate (0.9x) improves comprehension. For promotional or energetic content, a normal to slightly faster rate (1.0–1.1x) maintains engagement. Some tools support SSML (Speech Synthesis Markup Language) for fine-grained control of pauses, emphasis, and pronunciation.
Step 5: Generate and Download
Click Generate (or equivalent). The service creates the audio file—typically in seconds for short texts, minutes for long scripts. Preview it, then download as MP3, WAV, or the format offered. Import the file into your video editor, LMS platform, podcast tool, or app.
| Step | Action |
|---|---|
| 1. Open | Go to the online TTS tool (e.g. VideoDubber Text to Speech). |
| 2. Enter text | Paste or type your script; keep punctuation and structure clear. |
| 3. Choose language & voice | Select target language and voice style. |
| 4. Adjust prosody | (Optional) Set speed, pitch, or add SSML for fine control. |
| 5. Generate | Click Generate and wait for the audio. |
| 6. Download | Preview, then download the file for use in video, LMS, or elsewhere. |
Enter text, choose language and voice, then generate—convert text to speech online in minutes.
Cost of Online TTS: Free vs. Paid
Understanding the cost structure helps you pick the right tier and avoid unexpected overages on commercial projects.
Free online TTS usually comes with limits: a cap on characters or minutes per day, watermarks on audio, or restricted commercial use. Paid plans offer higher limits, more voices and languages, commercial rights, and typically higher quality from premium neural voice models.
As of 2026, paid online TTS typically runs from about $0.01 to $0.10 per 1,000 characters or a few dollars per hour of generated audio, depending on the provider and voice tier. Studio voiceover runs $50–$200+ per minute, making online TTS 50–200x more cost-effective for scalable narration.
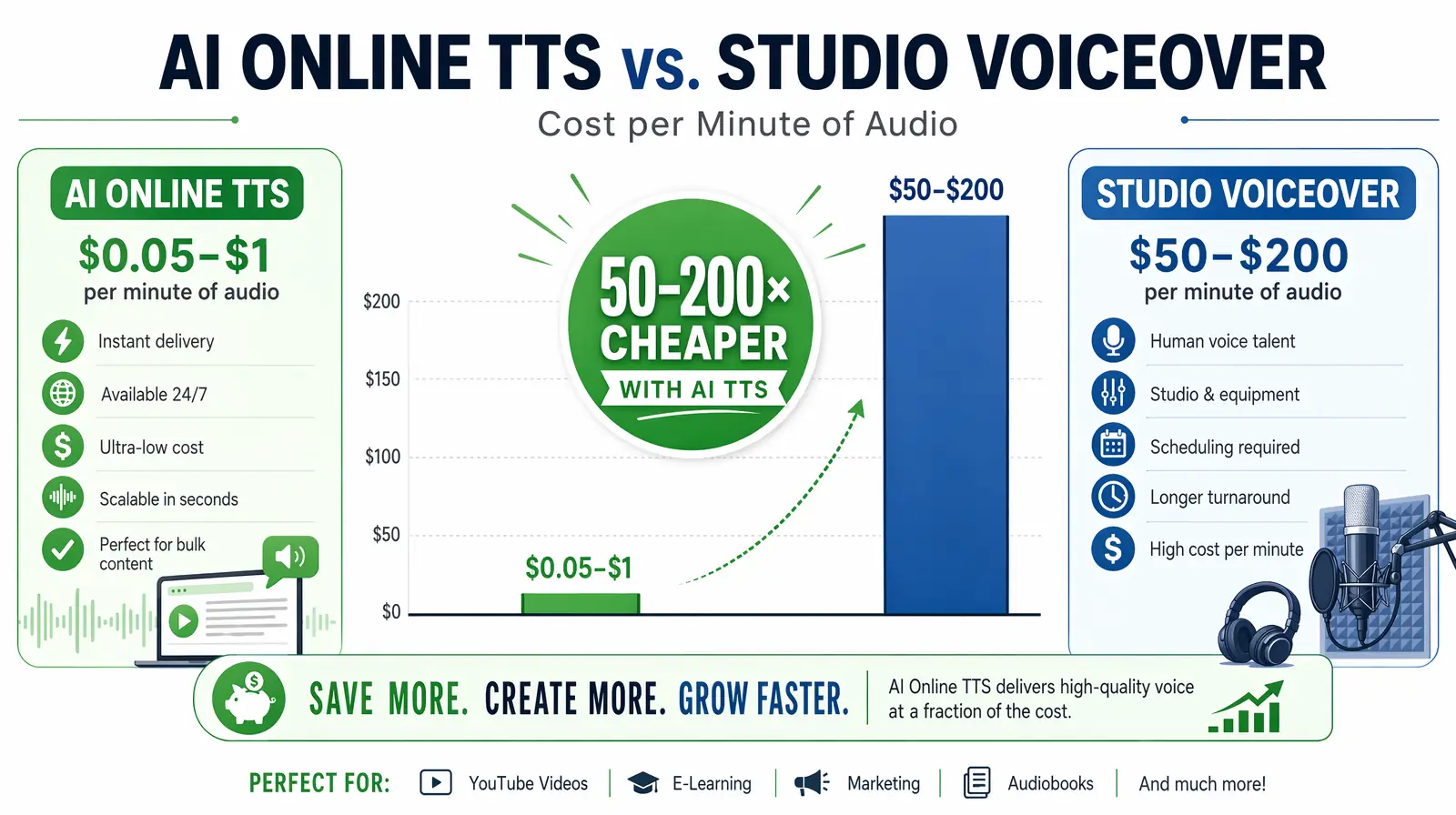
At $0.01–$0.10 per 1,000 characters, online neural TTS costs 50–200× less than $50–$200+ per minute studio voiceover — the core reason it has become the default for scalable narration.
| Tier | Typical limits | Typical use |
|---|---|---|
| Free | 1,000–5,000 characters/day; limited voices; non-commercial | Testing, personal use, short clips |
| Starter / Pro | 100K–500K characters/month; more voices; commercial use | Creators, small teams, regular voiceover |
| Enterprise / API | High volume; custom voices; SLA guarantees | Apps, e-learning platforms, large-scale dubbing |
For professional or commercial use—videos, courses, support content—a paid plan or usage-based pricing is usually required. Always check the provider's terms for commercial and redistribution rights before publishing content that includes AI-generated audio.
Is free TTS good enough for professional content?
Free tiers are suitable for testing and prototyping but typically have restrictions that make them unsuitable for commercial publication. For professional videos, online courses, or any content you monetize or distribute to customers, a paid plan with explicit commercial rights is the safe and correct choice.
Online TTS vs. Desktop vs. API
Choosing the right delivery method depends on how often you use TTS and where it needs to run.
| Factor | Online (browser) | Desktop app | API |
|---|---|---|---|
| Setup | None | Install and updates required | Integrate in code |
| Use case | One-off or occasional batches | Daily use, offline capability | Apps, automation, high-volume scale |
| Control | Manual clicks | Local UI, sometimes offline | Full programmatic control |
| Scalability | Limited by browser session | Limited by local machine | Unlimited via API calls |
| Best for | Most creators and small teams | Power users who prefer local tools | Developers, platforms, high volume |
For most people who want to convert text to speech online for videos, courses, or support content, a browser-based online TTS tool is the best fit: no install, no code, and you can generate and download audio in minutes. Use a desktop app if you need offline capability or prefer a persistent local interface. Use an API when you are building a product that must generate speech programmatically at scale.
What to Look for in an Online TTS Tool
Not all online TTS is equal. These criteria help you pick a tool that will sound professional and scale with your needs.
| Feature | Why it matters |
|---|---|
| Natural-sounding voices | Neural AI voices vs. older synthetic voices; listen to samples before committing. |
| Language coverage | More languages = better for video localization for EdTech and global content. |
| Voice variety per language | Multiple voices per language for different tones and styles. |
| Export format | MP3 and/or WAV for video and LMS compatibility. |
| Commercial license | Clear terms for use in paid, public, or commercial content. |
| Speed and limits | Character or time limits that match your production volume. |
| Prosody controls | Speed, pitch, pause, and SSML support for professional-grade output. |
| Integration with video workflow | Optional link to dubbing or video localization (e.g. VideoDubber TTS + video translation). |
VideoDubber is a strong option when you need text to speech online plus video dubbing and localization: one platform to generate voiceover and translate training or support videos into multiple languages with lip-sync and voice cloning, without switching tools between steps.
Use Cases: Videos, Audiobooks, E-Learning, Accessibility
Online TTS fits many scenarios where you need spoken audio from text quickly and affordably.
| Use case | How online TTS helps |
|---|---|
| Video voiceover | Generate narration for explainers, ads, product demos, or social clips without a mic, studio, or voice talent. |
| Audiobooks and long-form | Turn manuscripts, articles, or long-form content into audio; some tools support chapter-level export for LMS or podcast upload. |
| E-learning and training | Narrate training and internal videos or course scripts in one or many languages without per-language recording sessions. |
| Accessibility | Provide spoken versions of articles, FAQs, or UI labels for screen-reader users, low-vision audiences, or audio-first learners. |
| Multilingual content | One script → many languages; combine TTS with video translation for full localization. |
| Prototyping and review | Test pacing and tone before booking a voice artist; share audio drafts for stakeholder review in hours. |
| Customer support IVR | Generate on-hold messages, IVR prompts, and chatbot voice responses without a studio booking each time copy changes. |
EdTech and customer support are two areas where online TTS scales especially well: you can localize course narration and support or product demos into dozens of languages at a fraction of the cost of human dubbing, with consistent voice quality across every version.
Best Practices for Natural-Sounding TTS
Quality of input and tool choice have the biggest impact on how natural the output sounds. These practices consistently improve results:
-
Write for speaking, not for reading. Short sentences, clear punctuation, and natural phrasing. Avoid long, dense paragraphs or complex nested clauses. Read your script aloud before submitting—if it sounds awkward spoken, it will sound awkward as TTS.
-
Use the right voice for the content. Match voice style (formal, casual, energetic, warm) to the content type and target audience. A tutorial should use a clear, measured voice; a product announcement can be more energetic.
-
Control pace and emphasis. Many TTS tools support speed controls and SSML tags like
<break>and<emphasis>. Use them to add natural pauses after headings and before key points. -
Preview before full generation. Generate a 30-second sample from the middle of your script (not just the first line) before processing the full text. Middle sections often reveal pacing and terminology issues that the opening does not.
-
Batch wisely. For long texts, split into logical chunks (by section, scene, or module) so you can edit and re-generate only what needs changing without reprocessing the full piece.
-
Check numbers, acronyms, and proper nouns. TTS engines sometimes mispronounce these. Use the tool's pronunciation dictionary, phonetic spelling, or SSML
<say-as>tags to correct them before final export.
In practice, teams that script specifically for TTS—with consistent terminology, active voice, and clear structure—get noticeably better results than those who paste raw documentation or articles without editing for speech rhythm.
TTS vs. Voice Cloning: Which Do You Need?
Understanding the difference between standard TTS and voice cloning helps you choose the right tool for each project.
Text to speech (TTS) converts text into speech using the tool's built-in synthetic voices. You select from a library of voices, but you cannot make the system sound like a specific person.
Voice cloning creates a synthetic voice that mimics a specific person's tone, accent, cadence, and emotional style from a sample of their speech—typically 1–10 minutes of clean audio. Once cloned, the synthesized output sounds like that specific individual, not a generic AI voice.
| Factor | Standard TTS | Voice Cloning |
|---|---|---|
| Setup | No sample needed; instant | Requires 1–10 min audio sample |
| Voice identity | Generic synthetic voice from library | Sounds like the specific speaker |
| Best for | New content without a specific narrator | Preserving a specific presenter across languages |
| Use case | Articles, scripts, generic narration | Course instructor dubbing, CEO messages, support agent localization |
| Cost | Lower | Higher (additional processing) |
For video dubbing and localization, voice cloning is typically the better choice because it preserves the presenter's identity across all language versions. For original narration where no specific speaker identity is required, standard TTS from a high-quality voice library is sufficient and more cost-effective.
Tools like VideoDubber offer both: standard TTS for quick narration generation and voice cloning for video dubbing that preserves the original speaker's voice across languages—all in the same platform without switching tools mid-workflow.
Frequently Asked Questions
What is the best way to convert text to speech online?
Use an AI-powered online TTS tool that supports your target language and offers neural, natural-sounding voices. Paste your text, choose language and voice, generate, and download the audio. For video or multilingual projects, choose a tool that integrates with dubbing or localization (e.g. VideoDubber) so you can go from text to dubbed video in one workflow rather than stitching together multiple services.
Is there a free text to speech that sounds human?
Many online TTS tools offer free tiers with limited characters or minutes per day; quality has improved significantly so that even free tiers can sound quite natural for supported languages. For the most human-like result and for commercial use, paid plans with premium neural voices are the standard. Always listen to samples before committing to a tool for a production project.
How much does it cost to convert text to speech online?
Free tiers often allow a few thousand characters per day at no cost. Paid online TTS in 2026 typically ranges from about $0.01 to $0.10 per 1,000 characters or a few dollars per hour of generated audio, depending on provider and voice tier. Studio voiceover often runs $50–$200+ per minute, so online TTS is usually 50–200x cheaper for scalable narration.
Can I use online TTS for commercial projects?
Only if the tool's terms explicitly allow it. Many free tiers are for personal or non-commercial use only. Paid plans typically grant commercial and redistribution rights for videos, courses, and apps. Always read the license and terms before publishing commercial content that includes AI-generated audio.
How do I make text to speech sound less robotic?
Choose a tool with neural or AI voices. Write in short, natural sentences with correct punctuation. Use prosody controls (speed, pauses, emphasis) if the tool supports them. Preview and adjust; sometimes switching to a different voice or making small script tweaks (contractions, active voice, shorter sentences) makes the most significant difference in perceived naturalness.
What is the difference between TTS and voice cloning?
Voice cloning creates a synthetic voice that mimics a specific person's tone, accent, and style from a sample of their speech. Text to speech (TTS) converts text into speech using pre-built synthetic voices from the tool's library. Voice cloning gives you a custom narrator who sounds like a specific individual; standard TTS uses the tool's built-in voices. Some platforms, like VideoDubber, offer both in the same interface.
Can I use text to speech for YouTube or social media videos?
Yes, if your TTS provider's license allows commercial use and you follow the respective platform's terms. Many creators use online TTS for YouTube, TikTok, and Instagram voiceovers successfully. Ensure your script is original or properly licensed to avoid copyright issues, and verify that your TTS provider's terms cover monetized content distribution.
How many languages do online TTS tools support?
It varies significantly by provider. Leading online TTS services support 50–150+ languages and regional variants, including major world languages and many regional accents. VideoDubber's TTS supports a wide range of languages so you can generate voiceover or dubbed audio for global audiences from a single interface.
How long does it take to convert a 1,000-word article to speech?
Most online TTS tools process a 1,000-word article (approximately 5–7 minutes of audio) in 15–60 seconds once generation starts. Total time including pasting text, choosing settings, and downloading is typically under 5 minutes for most use cases. Longer texts may take 2–5 minutes to generate, depending on the provider's processing load and your plan tier.
Summary: Convert Text to Speech Online and Scale Your Voiceover
- Text to speech (TTS) online turns written text into spoken audio in the browser—no install, no studio. Modern AI TTS sounds natural and supports dozens of languages out of the box.
- To convert text to speech online: open a TTS tool, paste your text, choose language and voice, generate, and download. Use the audio in videos, e-learning, accessibility content, or apps.
- Online TTS is typically 50–200x cheaper than professional human narration (cents to a few dollars per minute vs. $50–$200+ per minute) and scales to many languages without per-language recording sessions.
- Pick a tool with neural voices, your required languages, clear commercial terms, and—if you do video—integration with dubbing or video localization.
- Best results come from writing scripts specifically for speech, choosing the right voice for your content type, using prosody controls for pacing, and previewing a sample before final export.
- TTS vs. voice cloning: use standard TTS for generic narration; use voice cloning for dubbing that must preserve a specific speaker's identity across languages.
Further Reading
How to Clone Celebrity Voices for Video Dubbing: Complete 2026 Guide
How to clone celebrity voices for video dubbing with AI — step-by-step guide covering audio quality, legal rules, use cases, and 150+ language support.
How to Change Speaker Voices in Video Translation: Complete Guide [2026]
Change speaker voices in video translation with step-by-step workflows for voice assignment, instant cloning, and Pro+ voice cloning. Full 2026 guide.
What is Voice Cloning? Complete Guide to AI Voice Replication
Voice cloning explained: how AI replicates any voice from 3 seconds of audio. Best 2026 models, pricing comparison, ethical guide, and use cases.
How to Translate Videos to Multiple Languages: The Complete 2026 Guide
How to translate videos to multiple languages with AI dubbing in minutes. Step-by-step workflow, cost data, voice cloning tips, and distribution strategy.
Best Alternative to ElevenLabs Video Translator (7 Point Comparison)
Discover the best alternative to ElevenLabs Video Translator. With a comprehensive 7-point comparison, see why VideoDubber.ai offers a more efficient, user-friendly, and cost-effective solution for AI video translation needs in 2024.