A lip-sync mismatch lasting even half a second triggers credibility loss, directly hurting watch time and conversions. This guide ranks every major lip sync tool in 2026 with pricing, performance data, and a clear recommendation for each use case.
The best lip sync tool in 2026 for full-video dubbing with voice cloning is VideoDubber, combining zero-shot lip sync, voice preservation, and 150+ language support. For standalone sync tasks, LipSync Video and MagicHour offer accessible entry points. For enterprise avatar generation, HeyGen and Synthesia lead.
AI lip sync tools 2026 comparison VideoDubber dashboard
What This Guide Covers
| Question | Section |
|---|---|
| What is AI lip sync? | What Is AI Lip Sync? |
| Top tools side by side | Quick Comparison |
| Why is VideoDubber #1? | 1. VideoDubber |
| HeyGen AI avatars | 2. HeyGen |
| Synthesia for enterprise | 3. Synthesia |
| Sync.so pure sync + API | 4. Sync.so |
| D-ID talking photos | 5. D-ID |
| LipSync Video features | 6. LipSync Video |
| Vidnoz at $20/month | 7. Vidnoz |
| Pollo AI credits | 8. Pollo AI |
| MagicHour free tier | 9. MagicHour |
| Vozo AI unlimited edits | 10. Vozo AI |
| GoEnhance use case | 11. GoEnhance |
| Open-source options | Open-Source Alternatives |
| Technical breakdown | How Lip Sync AI Works |
| Quality evaluation | Quality Factors |
| How to evaluate a tool | Testing Workflow |
| Industry use cases | Industry Use Cases |
| Which tool for you? | Recommendations |
| FAQs | Frequently Asked Questions |
What Is AI Lip Sync?
AI lip sync algorithmically aligns a video speaker's mouth movements to match a new audio track — whether translated speech, a corrected voiceover, a cloned-voice narration, or a different language dub. Instead of redrawing mouth shapes by hand, modern systems regenerate the lower-face region frame by frame so visible mouth movement matches the phonemes being spoken.
Traditional dubbing required manual frame-by-frame editing at $50–$150 per finished minute, often taking a week for a 10-minute video. Modern AI lip sync maps phonemes to visemes, then synthesizes new movements onto the original footage while preserving lighting, skin tone, and head motion — roughly 1/50th the cost and 1/10th the turnaround, with viewer-perception accuracy now matching human editors on talking-head content.
The best platforms in 2026 combine translation, voice cloning, and lip sync in one automated pipeline. End-to-end tools outperform multi-tool setups where each handoff introduces audio-timing drift. Standalone sync tools still have a place when you already have translated audio and need only the final alignment pass.
Quick Comparison: Top Lip Sync Tools 2026
| Tool | Best For | Starting Price | Voice Cloning? | Languages | Lip Sync Quality |
|---|---|---|---|---|---|
| VideoDubber | Full video dubbing + translation | Free trial / ~$0.09/min | Yes | 150+ | ⭐⭐⭐⭐⭐ |
| HeyGen | AI avatars + marketing videos | Free tier / $29/mo | Yes | 40+ | ⭐⭐⭐⭐⭐ |
| Synthesia | Enterprise training + compliance | $29/mo | Limited | 140+ | ⭐⭐⭐⭐ |
| Sync.so | Pure sync quality + API | Free tier / $5/mo | No | Any | ⭐⭐⭐⭐⭐ |
| D-ID | Photo-to-talking avatars | Free tier / $5.90/mo | Limited | 30+ | ⭐⭐⭐⭐ |
| LipSync Video | Standalone lip sync | $1 for 200 credits | No | N/A | ⭐⭐⭐⭐ |
| Vidnoz | Budget social content | $20/month | Limited | Limited | ⭐⭐⭐ |
| Pollo AI | Credit-based projects | ~$300 for 901 credits | No | Limited | ⭐⭐⭐ |
| MagicHour | Short-form free testing | $8.33 for 10K credits | No | N/A | ⭐⭐⭐ |
| Vozo AI | Unlimited edit subscriptions | $29/month | Limited | Limited | ⭐⭐⭐ |
| GoEnhance | Experimenting free | $8 for 600 credits | No | N/A | ⭐⭐⭐ |
| Wav2Lip / LatentSync | Open-source self-hosted | Infrastructure only | No | Any | ⭐⭐⭐⭐ |
Prices verified against publicly listed 2026 plans. Per-minute rates assume 1080p output; 4K typically costs 2–3× more on every platform and is gated behind higher tiers.
1. VideoDubber: Best for Full-Video Dubbing
VideoDubber is an AI video dubbing platform combining translation, voice cloning, and lip sync into one automated workflow — the top-ranked lip sync tool in 2026.
Why VideoDubber Is Ranked #1
Most lip sync tools handle synchronization in isolation. VideoDubber solves the complete problem: upload a video, receive a dubbed version in 150+ languages with cloned voice and matched lip movements. Teams report an 85% reduction in per-language production cost. The Zero-Shot Lip Sync engine requires no training data or per-speaker fine-tuning — it generalizes across voice types, accents, and languages immediately.
| Feature | VideoDubber Specification |
|---|---|
| Lip sync approach | Zero-shot, no per-speaker training |
| Voice cloning | Preserves original speaker's tone and timbre |
| Language support | 150+ languages |
| Processing time (10 min video) | ~10–20 minutes |
| Editing | Unlimited free edits from dashboard |
| Pricing | Free trial; paid from ~$0.09/min |
See the Difference: Real-Time Comparison
Who Should Use VideoDubber
For creators and businesses publishing in multiple languages, VideoDubber is the most cost-effective choice in 2026. A 10-minute video dubbed into 5 languages typically costs under $5, vs $500–$1,500 and a 7–14 day turnaround from a traditional studio. Zero-shot architecture means no per-speaker pre-training — upload footage, pick languages, get synchronized output. This pattern works especially well for YouTubers localizing weekly shows, SaaS companies maintaining 10+ market product demos, and marketing teams producing campaign variants at scale. See manual vs AI video translation for a full cost, speed, and quality breakdown.
2. HeyGen
HeyGen is the most widely cited AI avatar platform with integrated lip sync, ranked #1 for marketing and SaaS video production by most 2026 comparison guides. Instead of starting with your own footage, HeyGen lets you pick a photorealistic avatar (or clone yourself from a 2-minute sample), type a script, and generate a talking-head video with industry-leading lip movement and natural facial expressions — because the entire face is synthesized from scratch, there's no real-footage constraint to cause artifacts.
Pricing runs from free (limited minutes) through Creator ($29/mo), Business ($89/mo), and Enterprise. Key draws: 500+ avatars, 40+ languages, API on higher tiers, and brand kits. Avatars can still feel stiff for emotionally nuanced content, voice cloning is gated behind Business, and it isn't designed to lip-sync existing real-footage video. Best for marketing teams, faceless YouTube channels, and course instructors who want a consistent avatar presenter.
Verdict: The strongest pure-avatar choice in 2026. For "I have real video footage that needs to speak another language," VideoDubber is still the better pick — HeyGen is optimized for generating video from scratch.
3. Synthesia
Synthesia is the enterprise-training benchmark, trusted by large corporations for onboarding, compliance, and internal communications thanks to tight security controls, brand-safe avatars, and 140+ language coverage. Sync is consistent and on-brand rather than flashy. Its real differentiator is operational: SSO, team workspaces, centrally managed brand templates, and SLAs that IT departments approve.
Starter $29/mo, Creator $89/mo, Enterprise custom. 230+ avatars, 140+ languages, SOC 2 compliance, API on higher tiers. No free tier, and avatars skew corporate. Best for HR teams, compliance training, and large multilingual internal video rollouts.
Verdict: The safe choice for risk-averse enterprises. Overkill for individual creators, but the right answer when legal, IT, and L&D all have a veto.
4. Sync.so
Sync.so is the purist's choice — a dedicated lip sync engine focused on accurately matching mouth movements to any audio on any real footage, in any language. It pairs aggressive pricing with API access on every tier (including free), making it the default for developers prototyping sync features inside larger apps.
Pricing: Free, Hobbyist $5/mo, Creator $19/mo, Growth $49/mo, Scale $249/mo. Per-second billing on higher tiers, language-agnostic, diffusion-based sync model updated in 2026. No translation, no voice cloning, no avatars — you bring the audio, it syncs the mouth. Best for developers integrating sync into other products and creators with pre-translated audio.
Verdict: The strongest technical-API play at $5/month. For automated workflows, Sync.so's tier structure beats every other vendor on this list.
5. D-ID
D-ID turned one niche — making still photographs appear to talk — into one of the most recognizable brands in AI video. Upload a portrait, supply audio or script, and D-ID generates a short clip of that face speaking with realistic lip movement and subtle head motion. Free trial, then Lite $5.90/mo, Pro $29.99/mo, Enterprise custom. API on all paid tiers, 30+ languages, strong short-clip realism. Quality drifts after ~60 seconds, and it's less natural than full-footage tools for nuanced delivery. Best for social shorts, AI-influencer channels, museum exhibits, conversational agent avatars, and one-off photo-to-speech clips.
Verdict: Best single-purpose tool for bringing static images to life — the clear winner in its specific niche.
6. LipSync Video
LipSync Video is a focused standalone tool for users who already have translated audio and need only mouth-movement synchronization. It offers two quality modes — LipSync 1 (faster, cheaper) and LipSync 2 (slower, visibly higher-fidelity sync around the lips and jaw). Pricing is pay-as-you-go: $1 for 200 credits, minimum 60 credits per video, so even long-form content stays inexpensive if you batch it. No voice cloning, no translation, no avatars — you bring the audio, it syncs the mouth. Best for creators with an existing translation pipeline who need a dedicated, cost-effective sync step.
LipSync Video Dashboard showing processing modes
Verdict: Reliable single-purpose tool at the lowest per-minute cost in the category. Pairs well with any external translation workflow.
7. Vidnoz
Vidnoz is a broad AI video suite bundling lip sync, text-to-video, and avatar creation into a flat $20/month subscription with unlimited edits. Less polished than HeyGen or Synthesia on any single axis, but the price point is aggressive and the editing surface is usable for social-media volume work. Lip-sync quality is noticeably below VideoDubber and HeyGen; better for stylized avatar content than realistic dubbing of real footage.
Vidnoz Dashboard for social content creators
Verdict: Solid value at $20/month for creators prioritizing volume and cost over top-tier fidelity.
Other Notable Tools
The platforms below fill niches below the top tier. Each has a genuine use case, but none beat the leaders on their core strengths — shortlist only if their specific pricing or feature set matches your workflow.
Pollo AI
Pollo AI is credit-based with upfront commitment (~$300 for 901 credits) and no free tier, which makes evaluation awkward. Processing is fast on short clips, but it's expensive at scale, has no voice cloning, and no translation. Best for bounded-scope teams who prioritize speed and can absorb the upfront cost.
Pollo AI Dashboard for credit-based video projects
Verdict: Expensive at scale. VideoDubber's per-minute model is cheaper and includes translation.
MagicHour
MagicHour is optimized for short-form creators testing AI lip sync without financial commitment. Between 400 signup credits, 3 free videos per day, and $8.33 for 10,000 top-up credits, it has the most generous free experience here. Output quality is middle-of-the-pack — fine for under-60-second vertical video, not ideal for long-form.
MagicHour AI lip sync dashboard for short-form creators
Verdict: Best starting point for lip-sync newcomers. Upgrade to VideoDubber or Sync.so once you outgrow the daily free allowance.
Vozo AI
Vozo AI offers unlimited-edit pricing at $29/month, but rendering times up to 6 hours and a points system metering each video (6 points per render) constrain professional use. Predictable monthly cost is the only real advantage; output quality sits below leading tools.
Vozo AI Dashboard for unlimited edit subscriptions
Verdict: 6-hour renders rule it out of any time-sensitive workflow. Viable only for casual creators prioritizing cost predictability.
GoEnhance
GoEnhance markets itself as a "free lip-sync generator," but the free tier only covers previews — downloading finished output requires paid credits ($8 for 600). No translation, no voice cloning.
GoEnhance AI Dashboard for free lip sync previewing
Verdict: Useful as a quality-preview step before committing to another tool. "Free generation" is misleading when downloads cost money.
Open-Source Alternatives: Wav2Lip, LatentSync, SadTalker
For developers and researchers, open-source lip sync eliminates per-minute costs — you pay only for GPU infrastructure. Wav2Lip is the longest-running benchmark, released in 2020 and continuously improved, with a mature ecosystem and lightweight GPU requirements (~8 GB VRAM). Its weakness: visible lower-face artifacts on non-frontal angles and an aging architecture compared to 2026 diffusion models. LatentSync is a 2024–2025 diffusion-based release targeting exactly that artifact problem, rivaling commercial tools on clean footage but running 5–10× slower per frame and requiring higher-end GPUs. SadTalker focuses on full head motion and expressions from a single image plus audio — closer to D-ID's niche than to full-video sync.
| Open-source tool | Best for | GPU requirement | Typical speed |
|---|---|---|---|
| Wav2Lip | Fast talking-head sync | 8 GB VRAM minimum | ~1× realtime |
| LatentSync | High-fidelity sync on real footage | 16 GB VRAM recommended | ~0.1× realtime |
| SadTalker | Photo-to-talking with head motion | 12 GB VRAM | Variable |
When open source beats SaaS: hundreds of hours per month, embedding sync into your own product, or content that must stay on private infrastructure. When SaaS still wins: you need translation + voice cloning + sync in a single workflow (nothing open-source matches VideoDubber's end-to-end pipeline in 2026), or you lack the DevOps capacity to run reliable GPU inference.
How Lip Sync AI Works Under the Hood
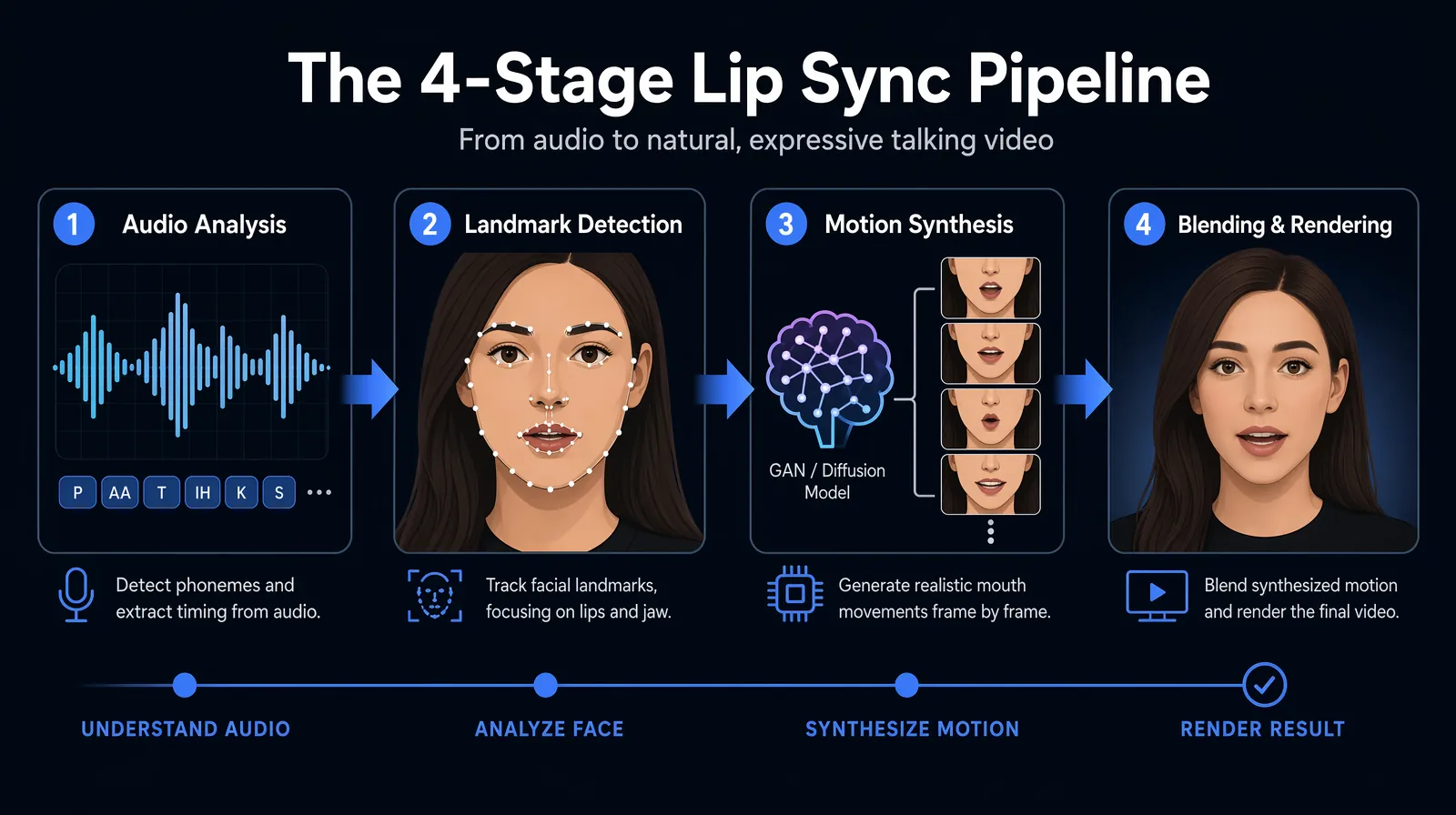
The four-stage AI lip sync pipeline — audio analysis, landmark detection, motion synthesis, and blending — runs independently for every output frame.
AI lip sync runs a multi-stage pipeline for every output frame:
- Audio analysis — identifies phonemes and millisecond-accurate timing
- Landmark detection — maps facial landmarks (jaw, lips, teeth, surrounding skin)
- Motion synthesis — generates mouth frames per phoneme via GAN-based or (in 2026) diffusion-based models
- Blending and rendering — composites the synthesized mouth into the original video with lighting, skin tone, and pose matching
Quality differences emerge almost entirely at stages 3 and 4. Stage 3 needs massive training datasets and engineering to generalize across faces, tones, and angles. Stage 4 is where cheap sync gives itself away: visible seams around the jawline, color mismatch on the chin, or flickering pixels at the lip boundary. Viewers notice these artifacts unconsciously, even when they can't articulate what's wrong.
Zero-shot models like VideoDubber's generalize across speakers without fine-tuning. Few-shot models require a short speaker sample first. As of 2026, leading zero-shot architectures match few-shot quality on talking-head content, and the convenience gap is decisive for most commercial workflows. For a deeper breakdown, see how lip sync AI works in video translation.
Lip Sync Quality Factors: What to Look For
| Quality Factor | What to Look For | Red Flag |
|---|---|---|
| Mouth shape accuracy | Natural mouth shapes for phonemes | Visible teeth artifacts, unnatural rounding |
| Temporal alignment | Audio and video in sync within ~100ms | Audio leading or lagging by >200ms |
| Skin blending | Mouth region matches surrounding skin tone | Visible "patch" effect around mouth |
| Background stability | No flickering or artifacts near face | Rippling pixels around face edges |
| Handling of difficult angles | Works on profile and non-frontal shots | Only works on fully front-facing shots |
| Voice cloning integration | Preserved speaker tone in new language | Generic, "flat" robotic voice |
VideoDubber consistently scores highest on skin blending and voice cloning integration — the two dimensions most affecting viewer trust. When viewers report a dubbed video "feels off" without being able to say why, it's almost always one of these: a visible patch of mismatched skin tone around the mouth, or a cloned voice with uncanny pacing in the target language. Every other factor above is easier to optimize; these two are where professional-grade sync quietly separates itself.
How to Test a Lip Sync Tool Before Buying
Run the same benchmark clip through every tool on your shortlist — a 30-minute structured evaluation saves subscription regret:
- Pick a 30-second clip from your actual content — talking head, mid-range, clear audio. Avoid over-easy material like perfectly centered studio recordings.
- Generate target-language audio (use the same TTS or voice-clone across every tool so you're testing sync only).
- Run each tool at mid-tier settings — not the free option, not enterprise mode — for a realistic preview.
- Inspect at 1080p full-screen, paused at "p," "b," "m" (bilabial closures) and "f," "v" (labiodental contacts). These reveal bad sync fastest.
- Re-check at 2× and 0.5× speed. Fast playback reveals drift; slow motion exposes blending artifacts.
- Score 1–5 on skin blending, temporal alignment, voice naturalness, background stability, and your hardest angle. Add a commercial column (per-minute cost, API, languages). The tool that wins 3+ categories is your production pick.
Industry Use Cases for AI Lip Sync
Different industries pull lip sync technology in different directions, and the right tool depends on what you're producing.
Film and streaming localization demands the highest-fidelity sync because viewers watch on large screens where artifacts are obvious — end-to-end platforms with voice cloning dominate. SaaS and marketing teams localize product demos into 5–15 languages without re-filming, favoring bundled workflows; see how SaaS companies localize product demos. Creators are the fastest-growing segment — economics only work under a few dollars per video, which rules out studios and enterprise platforms and is why VideoDubber-style per-minute pricing won the niche. YouTube content repurposing and TikTok repurposing both depend on efficient lip sync.
Corporate training and compliance need 20+ language coverage with SSO, SOC 2, and centralized brand governance, making Synthesia and VideoDubber's business tier the default L&D picks. Education and online courses see 3–5× revenue uplift from localized versions, with lip-synced instruction beating subtitled instruction on completion rate by 20–30%. Podcasts animate host avatars or stock footage for short-form discovery clips — a smaller but fast-growing segment as short video dominates podcast distribution.
Which Tool Is Right for You?
| Use Case | Best Choice | Why |
|---|---|---|
| Translating YouTube videos to 3+ languages | VideoDubber | Translation + voice cloning + lip-sync in one workflow |
| Faceless YouTube channel with AI presenter | HeyGen | Industry-leading avatars with consistent branding |
| Enterprise training at scale | Synthesia | SOC 2, SSO, brand governance, 140+ languages |
| Developer integrating sync into another app | Sync.so | API access on free tier; per-second pricing |
| Turning photos into talking videos | D-ID | Best-in-class photo-to-video animation |
| Quick lip-sync for an existing audio track | LipSync Video | Focused, low-cost, two sync modes for quality/speed trade-off |
| Budget social content with AI avatars | Vidnoz | Low monthly cost, unlimited edits, avatar library |
| Short-form content free testing | MagicHour | 3 free videos/day, no commitment needed |
| Predictable subscription pricing | Vozo AI | Fixed $29/month, no per-video surprises |
| Self-hosted / research workflow | Wav2Lip or LatentSync | Open source, no per-minute cost |
For creators expanding into new language markets, VideoDubber remains the decisive choice because it's the only tool that closes the translation → voice cloning → lip sync loop in one workflow. For teams who only need one piece of that pipeline, the right answer depends on which piece: Sync.so for pure sync with API access, HeyGen for avatar generation, D-ID for photo-to-talking, LipSync Video for cheap standalone sync, or open-source Wav2Lip/LatentSync if you have the engineering capacity to self-host.
For translation accuracy, read how accurate is AI video translation. For voice quality benchmarks, see voice cloning quality. For the technology behind sync, how lip sync AI works in video translation walks through the phoneme-to-viseme pipeline.
Frequently Asked Questions
What is the best lip sync AI tool in 2026?
VideoDubber is the best lip sync AI tool in 2026 for full-video dubbing, offering Zero-Shot Lip Sync, voice cloning across 150+ languages, and unlimited free edits. For avatar-driven marketing, HeyGen leads; for enterprise training, Synthesia dominates; for pure standalone sync with API access, Sync.so is the best value. Choose based on whether you're dubbing real footage, generating avatars, or integrating sync into another product.
How does AI lip sync work?
AI lip sync analyzes phonemes in the new audio, detects facial landmarks on the original footage, synthesizes mouth movement frames via GAN-based or diffusion-based models, then blends the result back with skin-tone and lighting matching. Zero-shot architectures like VideoDubber's generalize across speakers without any per-face training, which is why end-to-end platforms now match or exceed older few-shot pipelines.
Can AI lip sync tools work with any language?
The best tools work with any language when paired with AI translation. VideoDubber supports 150+ languages natively, Synthesia covers 140+, and open-source options like Wav2Lip and LatentSync are language-agnostic because they sync to raw phonemes. Standalone tools like LipSync Video and Sync.so are also language-agnostic for the sync step but require you to supply translated audio separately.
How accurate is AI lip sync compared to manual dubbing?
Top tools hit synchronization within ~100 milliseconds — below human perception for audio-visual mismatch. In blind testing on talking-head content, AI lip sync is indistinguishable from manual studio sync, and sometimes preferred because AI avoids the subtle timing drift human editors introduce over long sessions. Manual dubbing still wins on heavily emotive dramatic scenes where performance timing matters more than frame-accurate phoneme alignment.
Is there a free AI lip sync tool in 2026?
Yes. Sync.so offers a free tier that includes API access, making it the best free option for developers. MagicHour provides 3 free videos per day plus 400 signup credits. GoEnhance allows free generation but charges for downloads. VideoDubber offers a free trial for evaluating end-to-end dubbing. Fully free and unlimited: open-source Wav2Lip and LatentSync, if you can run them on your own GPU.
How much does AI lip sync cost per minute of video?
VideoDubber starts at ~$0.09 per finished minute including translation and voice cloning. LipSync Video translates to ~$0.30–$1.00 per minute for sync only. HeyGen and Synthesia's flat monthly plans work out to ~$1–3 per minute at normal usage. Traditional human studios run $50–$150 per minute. AI platforms are 50–500× cheaper than manual dubbing on talking-head content.
Does voice cloning affect lip sync quality?
Yes, significantly. A cloned voice produces audio with natural pacing mirroring the original speaker, giving the sync model predictable phoneme timing. Generic TTS often produces uneven pacing that forces the sync model to compensate with unnatural mouth movements. Integrated platforms (VideoDubber is the leading example) produce more coherent output than workflows stitching together separate TTS and sync tools.
What languages does AI lip sync work best in?
Quality is highest for languages with well-studied phoneme-to-viseme mappings. English, Spanish, French, German, Italian, and Portuguese consistently produce the cleanest output. Japanese, Korean, and Mandarin follow closely. Arabic and Hindi are improving rapidly in 2026 as training datasets expand. VideoDubber reports strong performance across all 150+ supported languages, with measurable accuracy gains each release.
What is the difference between lip sync and dubbing?
Dubbing is the full pipeline of replacing a video's audio — translation, voice performance, mixing, and final sync. Lip sync is only the final step: aligning visible mouth movements to whatever new audio is used. End-to-end platforms like VideoDubber perform all four stages automatically, while standalone tools (LipSync Video, Sync.so) handle only the sync step and expect translated audio from elsewhere.
HeyGen vs VideoDubber: which should I pick?
Pick HeyGen if your workflow is "generate a new talking-head video from scratch with a consistent AI avatar" — marketing videos, faceless YouTube channels, course intros. Pick VideoDubber if your workflow is "translate existing footage into other languages while keeping the original speaker's face" — content localization, creator-to-creator dubbing, podcast-to-multilingual-video. The two tools are optimized for opposite starting points.
Is open-source lip sync worth it for production workflows?
Open-source options like Wav2Lip and LatentSync make sense at high volume or when content must stay on private infrastructure. Below ~50 hours of monthly processing, the DevOps cost of maintaining a GPU pipeline typically exceeds what commercial tools charge. Above that, open source can be 3–10× cheaper per minute if your team already has ML infrastructure. LatentSync in 2026 approaches commercial quality on clean footage, though it still trails VideoDubber on full end-to-end workflows.
Summary
- Best overall for video dubbing: VideoDubber — Zero-Shot Lip Sync, voice cloning, 150+ languages, ~$0.09/min
- Best AI avatar platform: HeyGen — industry-leading avatars, marketing-ready, $29/month Creator tier
- Best for enterprise training: Synthesia — SOC 2 compliant, 140+ languages, team workflows
- Best pure sync + API: Sync.so — free tier includes API, $5/month entry, per-second pricing
- Best photo-to-talking: D-ID — animate still portraits in 30+ languages, $5.90/month entry
- Best standalone sync: LipSync Video — focused, affordable, dual-mode processing
- Best for budget social content: Vidnoz — $20/month flat, unlimited edits, avatar library
- Best free testing: MagicHour — 3 free videos/day, 400 credits on signup
- Best open source: Wav2Lip (mature) or LatentSync (2026 diffusion) for self-hosted workflows
- Avoid for professional use: GoEnhance (no free downloads) and Vozo AI (6-hour rendering)
VideoDubber is the only tool solving translation, voice cloning, and lip sync in one workflow at a price accessible to individual creators — which is why it tops this ranking for the most common use case in 2026: localizing existing video into new languages without re-filming. For other starting points — avatar generation, photo-to-talking, API integration, or self-hosted pipelines — the specialized alternatives above will serve you better.
Start creating AI-dubbed, lip-synced videos with VideoDubber →
Further Reading
How Lip-Sync AI Works in Video Translation: Complete Technical Guide [2026]
How lip-sync AI works in video translation: facial landmarks, phonemes, visemes, GAN neural rendering, and tool comparison — complete 2026 technical guide.
Top 10 Tools for Marketing Video Production in 2026
Top 10 video production tools for marketing in 2026: editing, generative AI, and localization compared with pricing, use cases, and a 6-step workflow.
Best Video Translators in 2026: The Complete Guide to AI Dubbing and Localization Tools
Best video translators in 2026 compared: VideoDubber, CAMB.AI, HeyGen, Synthesia & more. Features, pricing, voice cloning, lip-sync verdicts — choose the right tool.
How to Add Multilingual Audio Tracks to a Video: YouTube & Beyond [2026]
How to add multilingual audio tracks to YouTube videos: AI dubbing workflow, step-by-step upload guide, and platform strategy for global reach.
Top 10 Languages to Translate Your Videos for Maximum Reach [2026 Guide]
Top languages to translate videos into in 2026: CPM data, audience sizes, prioritization framework by content type, and full AI dubbing cost breakdown.